
Балки перекрытия в деревянном доме Расчет и выбор сечения.
Для сооружения прочного и надежного перекрытия выполняются расчеты для определения параметров конструкции. Цель расчета — определение оптимального соотношения размера сечения балок и расстояния между ними в конструкции. Это делается, чтобы избежать «играющих» перекрытий.
И так, цель поставлена: мы не хотим, чтобы в нашем доме при ходьбе, например, по второму этажу трясся весь дом. Выход прост – нужно правильно определить, какой пролет, каким сечением доски (балки) можно перекрывать.
Что такое балка?
Балка – линейный элемент несущей конструкции, опирающийся на оба конца и работающий преимущественно на изгиб. Материал изготовления у них может быть как дерево, так и метал. Металлические балки применяются при строительстве каменных домов.
Бывает несколько видов балок:
• Круглые (1) и овальные (2). Изготавливаются из бревна, предварительно очищают бревно от коры или используют оцилиндрованное бревно.
• Квадратные. Чаще всего используется брус (3). Его также не рекомендуют использовать в каркасном домостроении, по той же причине что и бревна-его не просушить, а сырое или бревно естественной влажности будет гнить;
• Прямоугольная (4 – составная балка (из доски), 5 — LVL брус,7 — доска), это самая распространённая форма. Такие типы прямоугольной балки можно просушить в камере, а это значит, что такие элементы не будут гнить, и им не нужна усадка.
• Двутавровые (6), такие балки называются так из-за их формы. Такая балка считается достаточно прочной, но ее изготовление дорогое.
Важно чтобы балки перекрытий были: сухие – допускается влажность, не превышающая 14%; сорт использованной доски должен быть А, В; обработанные специальным составом – огнебиозащитой, для того чтобы дерево не гнило и была повышенная огнестойкость.
Первое что мы должны понять — что при определении параметров конструкции учитывается: длина перекрытия (которая приравнивается к ширине перекрываемого пролета), сечение доски (балки), расстояние между балками (шаг балок) и величина нагрузки, оказываемой на них.
Теперь о каждом пункте подробнее.
1. Длина перекрытия.
Длина перекрытия – расстояние между несущими элементами (стена, опора), на которые будут опираться балки.
Длину перекрытий нам нужно знать для того, чтобы правильно выбрать длину балки ведь она берется с учетом запаса для опирания на стены.
Глубина опирания на стены берется на основании того из какого материала построен дом. Для кирпича или блочных стен: опирание 10-12 см при условии использования доски и 15 см при использовании бруса. Для изготовления перекрытия в бревенчатом (или брусовом) доме балки устанавливаются в зарубки в стенах на глубину не менее 7 см. В каркасном доме опирание балок не менее 10 см.
В каркасном доме опирание балок не менее 10 см.
Вычислить ширину пролета, которую вам нужно перекрыть, не сложно, это можно сделать обычной рулеткой. Главное знать максимальную длину пролета, которую перекрывает балка с определенным сечением. Чтобы не запоминать кучу цифр можно воспользоваться специальными онлайн — калькуляторами для расчетов.
|
Давайте рассмотрим на примере наших сечений:
Мы используем доску сечением 45х195 мм, такое сечение доски позволит перекрыть пролет до 4 метров. Если поменять сечение и взять доску 45х145 мм, то такой доской можно перекрыть пролет только до 2,5 метров. Пролет до 5 метров можно перекрыть брусом сечением 200х200 мм, но использовать его мы вам не рекомендуем, лучше взять балку составного сечения (две доски сечением 45х145мм и скрепить их металлозубчатой пластиной (МЗП)). Получается, что обычной доской можно перекрыть пролет только до 4 метров, если хочется пролет больше, то нужна тяжелая артиллерия в виде ферм, LVL бруса или двутавровых балок. |
 Мы не будем останавливаться на LVL брусе или двутавровых балках все характеристики задает завод изготовитель, поэтому что-либо о них сказать очень сложно. Мы используем фермы на металлозубчатых (гвоздевые) пластинах — МЗП.
Мы не будем останавливаться на LVL брусе или двутавровых балках все характеристики задает завод изготовитель, поэтому что-либо о них сказать очень сложно. Мы используем фермы на металлозубчатых (гвоздевые) пластинах — МЗП.Мы изготавливаем фермы 2 видов: сдвоенная и с параллельными поясами
2. Сечение балок деревянного перекрытия
Зная длину балок деревянного перекрытия (А) и определив общую расчетную нагрузку можно определить необходимое их сечение (или диаметр) и шаг укладки, которые связаны между собой. Считается, что лучшим является прямоугольное сечение балки деревянного перекрытия, с соотношением высоты (H) и ширины (В) как 1,4:1.
Чаще всего высота и шаг балок зависит от выбранной толщины утеплителя, для того чтобы не оставлять обрезков, столь дорогостоящего материала.
Также шаг балок зависит от нагрузки на перекрытия. Например, шаг балок в чердачных перекрытиях (неэксплуатиромого чердака) будет отличаться от шага балок в межэтажных и цокольных перекрытиях, но о нагрузках позже.
Ниже сводные таблицы, где представлено, какие пролеты каким сечением доски перекрываются и какой при этом должен у этой балки быть шаг.
Таблица расчета балок межэтажных перекрытий и нежилого чердака. Расчеты для сухих строганных пиломатериалов хвойных пород сортностью не ниже 2го сорта
Если балки будут крепиться с помощью крепежных элементов (уголки, кронштейны, хомуты), то за длину деревянных балок принимают ширину пролета
3. Расчет нагрузки на перекрытия.
Такой расчет производят в момент проектирования. Он включает в себя учет веса самих перекрытий и всё, что будет находиться внутри комнаты, с учетом тех, кто будет там передвигаться.
Стандартной временной равномерно распределенной нагрузкой принято считать 2,4кПа. Это значит, что в расчете учитывался вес:
- нагрузка от собственного веса элементов перекрытия (конструкций перекрытия, утеплителя, чернового и чистового пола, подшивки, а также отделки потолка, если это межэтажное перекрытие). При отсутствии стяжки, это нагрузка ок. 50кг на 1м2.
- временной нагрузки это нагрузки от всего остального: мебели, людей, домашних любимцев и т.д. эта нагрузка и есть 2,4кПа, т.е. ок.250кг на 1м2.
При использовании чердачного пространства для устройства мансарды, необходимо учесть вес полов, перегородок, мебели. В этом случае общую расчетную нагрузку необходимо увеличить до 350-400 кг/м2.
Более подробные правила расчета перекрытий можно найти в СП 20.13330.2016 «Нагрузки и воздействия».
Расчет деревянных балок перекрытия | Архитектурный журнал ADCity
3232
Правильный подбор балок, точность их размеров является определяющим фактором для надежности всего перекрытия. Деревянные балки перекрытия изготавливаются после точного расчета их длины и сечения. Длина их зависит от ширины будущего перекрытия, а сечение рассчитывается исходя из шага установки, планируемой нагрузки и длины пролета. В этой статье будут описаны некоторые нюансы выбора балок, указана методика их расчета.
Длина деревянных балок перекрытия, их количество и размеры определяются после проведения измерений пролета, который планируется перекрыть с их помощью. Важно учитывать глубину, на которую балки будут введены в стены, как они будут в них закреплены.
В стены, сложенные из блоков и кирпича, балки должны заходить на глубину не менее 150 мм (если они изготовлены из бруса) и на 100 мм – для досок. В деревянных домах балки врубаются в стены минимум на 70 мм.
Длина балок может быть равна пролету при использовании кронштейнов или уголков: в этом случае металлические поддерживающие конструкции принимают на себя вес перекрытия и остальной нагрузки. 22(5)
22(5)
Обычно ширина пролета, который может быть перекрыт с помощью деревянных балок – в пределах 2,5… 4,0 м. Максимальная длина балки из бруса или доски составляет 6 м. Если проект дома требует применения более длинных балок, необходимо использовать клееный брус или предусматривать возведение промежуточных опор (стен-перегородок).
Перекрытие передает балкам нагрузку, которая суммируется из собственного веса конструкции (включая вес межбалочного утеплителя и подшивных досок) и веса предметов, размещенных на перекрытии. Точный расчет выполнить можно только силами специальной проектной организации. Более простые способы расчета доступны для самостоятельного выполнения по следующей схеме.
Для чердачных перекрытий с подшивной доской (не несущих больших нагрузок, но утепленных минеральной ватой) справедливо утверждение о том, что на 1 м² в среднем действует нагрузка в 50 кг. В таком случае нагрузка на данное перекрытие будет равно: 1,3 × 70 = 90 кг/м² (согласно СНиП 2.01.07-85 цифра 70 (кг/м²)– нормированная нагрузка для данного перекрытия; 1,3 – коэффициент запаса прочности). Общая нагрузка равна 90 50 = 130 кг/м².
Общая нагрузка равна 90 50 = 130 кг/м².
Если межбалочный утеплитель тяжелее, чем минеральная вата или использовалась подшивка из толстых досок, то нормативную нагрузку считают равной 150 кг/м². Тогда: 150 × 1,3 50 = 245 кг/м² — общая нагрузка.
Если балки являются частью межэтажного перекрытия – расчетная нагрузка принимается равной 400 кг/м².
Определив длину балок и зная расчетную нагрузку, можно рассчитать шаг балок деревянного перекрытия и их сечение (в случае применения бревен – диаметр). Эти величины связаны между собой. Для этого пользуются следующими правилами.
Оптимальное соотношение высоты балки к ширине — 1,4:1. Деревянные балки перекрытия, размеры которых зависят от вышеуказанных параметров, могут быть шириной в пределах 40… 200 мм. Высота или толщина деревянных балок перекрытия подбирается соответствующей толщине утеплителя и обычно варьируется от 100 до 300 мм. Если используются бревна – их диаметр находится в пределах 110… 300 мм.
Если используются бревна – их диаметр находится в пределах 110… 300 мм.
Шаг укладки балок выбирают в диапазоне 300… 1200 мм, причем также принимают во внимание размеры листов утеплителя и материала подшивки. В случае возведения каркасных строений шаг балок должен быть равен расстоянию между стойками каркаса. shema146
Допустимый изгиб балок – 1/200 (для чердаков) и 1/350 – для межэтажных перекрытий. Приведено соотношение к длине перекрываемого пролета.
Расчет сечения деревянных балок перекрытия можно выполнить (кроме вышеуказанных способов), воспользовавшись таблицами специальной справочной литературы. Существуют также специальные компьютерные программы.
К примеру, для расчетной нагрузки 400 кг/м², соответствующей межэтажным перекрытиям, соотношение между шагом, шириной пролета и сечением следующее:
для шага 0,6 м и ширине пролета в 2,0 м сечение должно быть не менее 75×100 мм;
для шага 0,6 м и ширине пролета в 3,0 м сечение должно быть не менее 75×200 мм;
для шага 0,6 м и ширине пролета в 6,0 м сечение должно быть не менее 150×225 мм;
для шага 1,0 м и ширине пролета в 3,0 м сечение должно быть не менее 100×150 мм;
для шага 1,0 м и ширине пролета в 6,0 м сечение должно быть не менее 175×250 мм.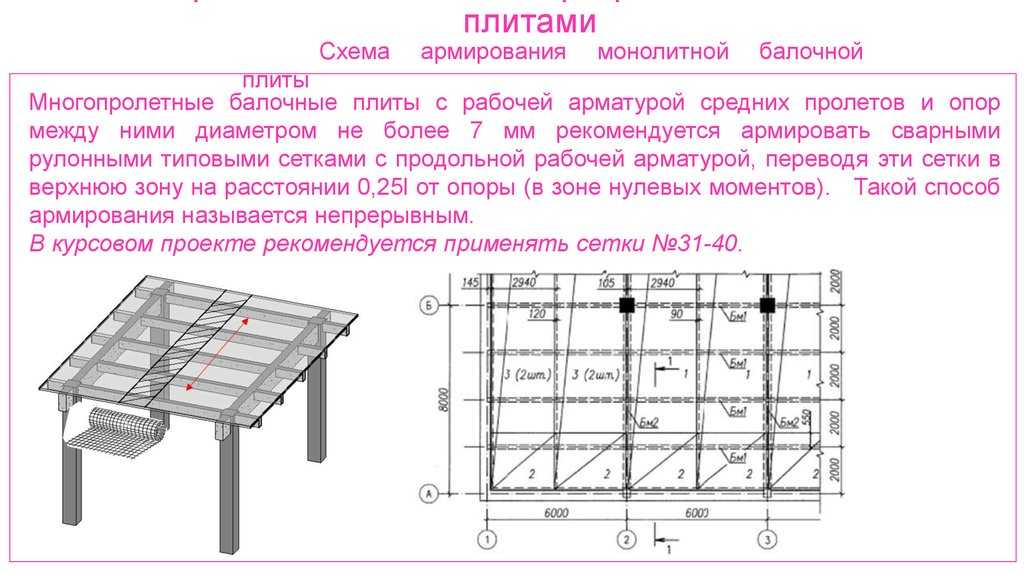
Основные требования к балкам перекрытия
Балки изготавливают из древесины хвойных деревьев: она обладает достаточной прочностью. Влажность материала не должна превышать 14%: превышение этого параметра может стать причиной прогиба лаг под нагрузкой.
Не допускаются пороки древесины, такие как синюшность, поражение плесенью, насекомыми-вредителями и грызунами.
Перед укладкой балки обрабатывают антисептическим составом.
Балка будет устойчива к изгибу, если ее стороны имеют соотношение по размерам как 7:5 (для брусьев).
Прочность на изгиб определяется высотой лаг: чем больше значение этого параметра – тем большую нагрузку без прогиба выдержит балка.
Чтобы перекрытие оставалось ровным даже под воздействием нагрузки, следует вытесать строительный подъем. Потолок нижнего яруса в этом случае будет иметь небольшой подъем в центральной части, но с увеличением нагрузки на перекрытие, он выровняется.
При частой укладке лаг брусья и бревна допускается заменять досками, уложенными на ребро.
Расход древесины будет более экономичным при изготовлении балок толщиной 50 и высотой 150… 180 мм. Ширина шага укладки при этом должна быть 400… 600 мм (это удобно для укладки плит утеплителя)
балок, деревянных, перекрытия, расчет
Расчеты деревянных балок перекрытия — онлайн расчет по формуле
В любом здании имеются перекрытия. В собственных домах при создании опорной части, применяются деревянные балки, которые обладают рядом потребительских свойств:
- доступность на рынке;
- лёгкость обработки;
- цена значительно ниже, нежели на стальные или бетонные конструкции;
- высокая скорость и удобство монтажа.
Но, как и всякий строительный материал, деревянные балки имеют определённые прочностные характеристики исходя из которых производится расчёт на прочность, определяются необходимые размеры силовых изделий.
- Основные виды балок ↓
- Нагрузки на горизонтальное перекрытие ↓
- Как рассчитать нагрузку на балку перекрытия ↓
- Пример расчёта ↓
- Как рассчитать необходимое количество балок ↓
- Пример расчёта ↓
- Как рассчитать необходимое сечение традиционной деревянной балки перекрытия ↓
- Пример расчёта ↓
Основные виды балок
При бытовом строительстве используются несколько типов монтажа опорных элементов перекрытий:
- Простая балка, — представляет собой перекладину, имеющую две опорные точки на своих концах.
 Расстояние между опорами называется пролёт. Соответственно, при наличии нескольких точек крепления, бывают двух–, трёх–, и более пролётные неразрезные балки. В конструкции частного дома в этом качестве выступают промежуточные стеновые перегородки.
Расстояние между опорами называется пролёт. Соответственно, при наличии нескольких точек крепления, бывают двух–, трёх–, и более пролётные неразрезные балки. В конструкции частного дома в этом качестве выступают промежуточные стеновые перегородки. - Консоль, — брус жёстко закреплён одним концом в стене или имеет один свободный конец, с длиной более чем двукратный поперечный размер. Наличие двух свободных свисающих частей говорит о том, что наличествует двухконсольная конструкция. На практике – это горизонтальные балки, входящие в состав крыши и образующие навес.
- Заделанное изделие, — оба окончания жёстко вмонтированы в стену. Такая схема встречается при возведении вышерасположенных перегородок и стен, при этом балка получается вмонтированной в вертикальную конструкцию.
Нагрузки на горизонтальное перекрытие
Для расчёта на прочность необходимо знать нагрузки, возникающие в процессе эксплуатации перекрытия. Самые значительные величины возникают на первом этаже жилого здания. Меньшие значения получаются для мансардных конструкций и чердачных помещений. Напряжения в балке возникают:
Самые значительные величины возникают на первом этаже жилого здания. Меньшие значения получаются для мансардных конструкций и чердачных помещений. Напряжения в балке возникают:
- от внутренних строительных конструкций, например, перегородок, лестниц;
- от веса бытовой техники, мебели;
- от массы людей.
Статическую нагрузку определяет два основных вида напряжения, – прогиб по всей длине и изгиб в месте опоры.
- Прогиб, – получается от веса вышерасположенных элементов. Максимальная стрелка отклонения получается в точке местонахождения объекта с самой большой массой и (или) посередине между опорами.
- Изгиб или излом, – это разрушение перекладины в точке заделки. Возникает от вертикальной нагрузки, а сама балка, воспринимающая это напряжение, выступает в роли рычага. С определённой величины усилия начинается критический изгиб, приводящий к разрушению поперечной опоры.

Для уменьшения влияния на прочность деревянного поперечного изделия от внутренних конструкций, их стараются располагать в местах нахождения нижних опор. Бытовую технику и мебель по возможности, целесообразно размещать вдоль стен или около разгрузочных конструкций.
Существует достаточно много типов деревянных балок, но наиболее доступны для широкой массы населения – это изделия прямоугольного или овального сечения. В последнем случае, балка представляет собой оцилиндрованное бревно, обрезанное с двух противоположных сторон.
Как рассчитать нагрузку на балку перекрытия
Общая нагрузка на элементы перекрытия складывается из собственного веса конструкции, веса от внутренних строительных изделий, опирающихся на балки, а также массы людей, мебели, бытовой техники и прочей хозяйственной утвари.
Полный расчёт, учитывающий все технические нюансы, достаточно сложен и выполняется специалистами при проектировании жилого дома. Для граждан, возводящих жильё по принципу «самостроя», более удобна упрощённая схема, в которую заложены требования СНиП, оговаривающие условия и технические характеристики деревянных материалов:
- длина опорной части балки, контактирующей с фундаментом или стеной, не должна быть меньше 12 см;
- рекомендуемое соотношение сторон прямоугольника 5/7, — ширина меньше высоты;
- допустимый прогиб для чердачного помещения составляет не более 1/200, межэтажные перекрытия – 1/350.

По СНиП 2.01.07–85 эксплуатационная нагрузка на чердачную конструкцию с лёгким утеплителем из минеральной ваты составит:
Пример расчёта
Дано:
- чердак в жилом доме, использующийся для хранения различного хозяйственного инвентаря;
- для утепления применён керамзит с лёгкой бетонной стяжкой.
Общая нагрузка составит G = 50 кг/м² + 150 кг/м² * 1,3 = 245 кг/м².
Исходя из практики, средние усилия на мансардном этаже не превышают значений в 300–350 кг/м².
Для межэтажных перекрытий величины находятся в диапазоне 400–450 кг/м², причём большее значение следует принимать при расчётах первого этажа.
Совет. При выполнении перекрытий целесообразно принимать значения нагрузок, превышающие расчётные на 30–50%. Это повысит надёжность конструкции в целом и увеличит общий срок эксплуатации.
Как рассчитать необходимое количество балок
Число поперечных опор определяется нагрузками, приходящиеся на них, и максимальным прогибом чернового покрытия, выполненного, например, из доски или фанеры. На их жёсткость влияет собственная толщина изделий и шаг между точками опоры, то есть, расстояние от соседних балок.
На их жёсткость влияет собственная толщина изделий и шаг между точками опоры, то есть, расстояние от соседних балок.
Для помещения с малой эксплуатацией (чердак), допускается использовать доску толщиной не менее 25 мм, при шаге между опорами 0,6–0,75 метра. Межэтажное перекрытие жилой зоны целесообразно осуществлять половой доской с размером не менее 40 мм и расстоянием по ближайшим точкам крепления не более 1 метра.
Пример расчёта
Чердачное пространство. Длина между стенами составляет 5 метров. Слабая эксплуатационная нагрузка, – хранение всякой утвари. Настил осуществляется из обрезной сухой доски хвойных пород толщиной 25 мм. Принимая максимальный шаг в 0,75 метра, количество опорных точек должно составить:
5 м / 0,75 м = 6,67 шт., округляя до целого числа в большую сторону – 7 балок.
Тогда уточнённый шаг равен:
5 м / 7 шт = 0,715 м.
Межэтажное перекрытие. Длина между стенами 5 метров. Первый этаж с максимальной нагрузкой. Черновой пол выполняется из изделия с размером 40 мм. Шаг по опорам принимается в 1 метр.
Первый этаж с максимальной нагрузкой. Черновой пол выполняется из изделия с размером 40 мм. Шаг по опорам принимается в 1 метр.
Количество точек крепления составляет: 5 м / 1 м = 5 шт.
Совет. Несмотря на невысокую нагрузку, приходящуюся на чердачное пространство, целесообразно применять требования, относящиеся к межэтажным перекрытиям, — в будущем может появиться вероятность перестройки в жилое мансардное помещение.
Как рассчитать необходимое сечение традиционной деревянной балки перекрытия
Прочностные характеристики опорного элемента определяются геометрическими параметрами, – длиной и поперечным сечением. Длина, как правило, даётся из внутренних размеров межстенного пространства и закладывается на стадии проектирования здания. Второй параметр, – сечение, можно изменять в зависимости от предполагаемых нагрузок в процессе строительства.
Пример расчёта
Чтобы избежать достаточно мудрёных математических выкладок, приводим рекомендуемые данные, которые сведены в таблицу. При имеющихся размерах пролёта и шага, можно определить примерное сечение бруса или диаметр бревна. Расчёт осуществлялся исходя из усреднённой нагрузки в 400 кг/м²
При имеющихся размерах пролёта и шага, можно определить примерное сечение бруса или диаметр бревна. Расчёт осуществлялся исходя из усреднённой нагрузки в 400 кг/м²
Таблица 1
Сечение прямоугольного бруса:
| Шаг, метр | Пролёт, метр | ||||
| 2,0 | 3,0 | 4,0 | 5,0 | 6,0 | |
| 0,6 | 75 х 100 | 75 х 200 | 100 х 200 | 150 х 200 | 150 х 225 |
| 1,0 | 75 х 150 | 100 х 175 | 125 х 200 | 150 х 225 | 175 х 250 |
Таблица 2
Диаметр оцилиндрованного бревна:
| Шаг, метр | Пролёт, метр | ||||
| 2,0 | 3,0 | 4,0 | 5,0 | 6,0 | |
| 0,6 | 110 | 140 | 170 | 200 | 230 |
| 1,0 | 130 | 170 | 210 | 240 | 270 |
Примечание: В таблицах приведены минимальные допустимые размеры. При проектировании собственного здания, необходимо принимать те размеры деревянных изделий, которые присутствуют на местном строительном рынке региона, причём значения требуется округлять в большую сторону.
При проектировании собственного здания, необходимо принимать те размеры деревянных изделий, которые присутствуют на местном строительном рынке региона, причём значения требуется округлять в большую сторону.
Совет. При отсутствии необходимого бруса, его можно заменить досками, скреплёнными между собой посредством столярного клея и саморезов. Ещё один вариант усиления – увеличить сечение бруса, добавив к его боковым сторонам доски определённой толщины.
Совет. Продлить срок службы и снизить показатель горючести поможет обработка специальными огне– и биозащитными средствами. Кроме этого, такая операция способствует небольшому увеличению прочности деревянных изделий.
Совет. Тем, кто всё-таки желает провести математические изыскания, по расчётам деревянных балок, для перекрытий, целесообразно заглянуть в интернет с этим вопросом, — имеется достаточное количество сайтов, на которых выложены электронные калькуляторы по определению параметров элементов силовых конструкций.
Статья была полезна?
0,00 (оценок: 0)
Расчет статистики для перекрывающихся и непересекающихся окрестностей — ArcGIS Pro
В этом разделе
- Форма окрестности
- Типы статистики окрестностей
Доступно с лицензией Spatial Analyst.
Операции с соседями вычисляют выходные значения, вычисляя указанную статистику для всех входных ячеек, содержащихся в каждом районе. Окрестность — это движущееся окно, которое перебирает входные данные.
В Spatial Analyst существует два основных типа операций с соседями: операции, при которых окрестности местоположений обработки перекрываются, и операции, при которых окрестности не перекрываются.
Инструмент Фокальная статистика обрабатывает входной набор данных с перекрывающимися соседями. Инструмент Block Statistics обрабатывает данные с неперекрывающимися соседями.
В фокальной операции только обрабатывающие ячейки получают результат вычисления всех ячеек в окрестности, тогда как в блочной операции каждая ячейка в пределах минимального ограничивающего прямоугольника, содержащего окрестность, получает одно и то же выходное значение.
Форма соседства
Определенные формы соседства, которые можно указать, представляют собой прямоугольник любого размера, круг любого радиуса, кольцо (в форме пончика) любого радиуса и клин в любом направлении.
В дополнение к этим геометрическим фигурам вы также можете создать окрестность неправильной формы, часто называемую ядром, где вы можете контролировать, какие именно ячейки окрестности будут включены в расчеты. Кроме того, вы также можете применять разные веса к определенным ячейкам по соседству.
Ячейки входного растра, попадающие в указанную окрестность, будут включены в вычисления, выполняемые для этой окрестности.
Для получения более подробной информации о том, как определенные ячейки включаются в соседство, см. справочные темы по отдельным инструментам или см. следующие темы:
- Как работает статистика блоков
- Как работает статистика очагов
- Как работает статистика точек
Типы статистики района
Для значений ячеек в обрабатываемой окрестности можно вычислить различную статистику:
- Для Фокальной статистики результат расчета применяется только к местоположениям, соответствующим обрабатываемой ячейке на выходном растре.
- Для статистики по блокам результат вычисления применяется ко всем ячейкам, находящимся в области обработки.
| Статистика | Описание |
|---|---|
Большинство | Определяет, что чаще всего встречается в окрестностях |
максимум | Определяет максимальное значение. Вычисляет среднее значение в окрестности |
Медиана | Вычисляет медиану значений в окрестности |
Minimum | Determines the minimum value in the neighborhood |
Minority | Determines the value that occurs least often in the neighborhood |
Percentile | Определяет указанное значение процентиля ячеек в окрестности. |
Диапазон | Определяет диапазон значений в окрестностях |
Стандартное отклонение | Computes Стандартное отклонение значений в соседстве |
Variety | Определяет количество уникальных значений в окрестности |
 Этот параметр доступен только для инструмента Фокальная статистика.
Этот параметр доступен только для инструмента Фокальная статистика.Похожие темы
Отзыв по этой теме?
SLDMS: инструмент для расчета перекрывающихся областей последовательностей
Введение
Из-за ограничений существующей технологии секвенирования генов мы не можем напрямую получить всю последовательность генов, а можем использовать только существующие методы секвенирования для секвенирования генов вида для тестирования для создания фрагментов последовательности, а затем для дальнейшей сборки генома для восстановления исходных генов.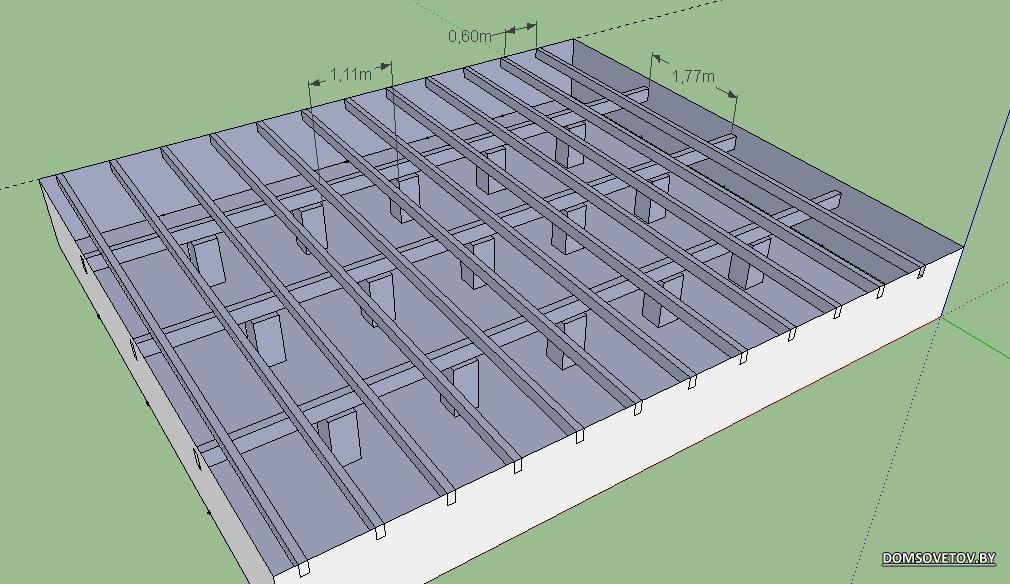 Проблема сборки генома также является одной из самых важных и сложных проблем биоинформатики на сегодняшний день.
Проблема сборки генома также является одной из самых важных и сложных проблем биоинформатики на сегодняшний день.
Двумя алгоритмами, обычно используемыми при сборке генома, являются алгоритм консенсуса перекрытия-макета (OLC) (Li, 2012) и алгоритм дебрейн-графа (DBG) (Li, 2012), которые используют разные методы для преобразования проблема сборки в задачу, связанную с теорией графов. Создавая взвешенный по ребрам граф данных секвенирования, результирующий взвешенный по ребрам граф обрабатывается, чтобы найти соответствующую информацию о пути в графе для использования в последующей работе по сборке генома. Все алгоритмы выводят оптимальный путь из взвешенного по ребрам графа, чтобы получить начальный контиг (Хуанг, 19 лет).92).
Большинство приложений для сборки генома основаны на одном из алгоритмов, таких как Canu (Koren et al., 2017), который использует алгоритм MHAP (Koren et al., 2017) для обнаружения перекрытия зашумленных последовательностей для получить перекрывающиеся области между последовательностями. Кроме того, программное обеспечение Flye (Lin et al., 2016) использует алгоритм ABruijn (Lin et al., 2016) для объединения алгоритмов OLC и DBG, генерирует собственный уникальный граф A-brijn-graph (ABG) и получает перекрывающиеся области узлов в графе, и некоторые другие программы сборки также могут выполнять ту же работу. Эти программы обычно требуют больше времени в процессе выравнивания последовательностей. Например, Flye требуется больше времени для поиска перекрывающихся областей последовательностей, а Canu медленнее исправляет данные секвенирования и т. д.
Кроме того, программное обеспечение Flye (Lin et al., 2016) использует алгоритм ABruijn (Lin et al., 2016) для объединения алгоритмов OLC и DBG, генерирует собственный уникальный граф A-brijn-graph (ABG) и получает перекрывающиеся области узлов в графе, и некоторые другие программы сборки также могут выполнять ту же работу. Эти программы обычно требуют больше времени в процессе выравнивания последовательностей. Например, Flye требуется больше времени для поиска перекрывающихся областей последовательностей, а Canu медленнее исправляет данные секвенирования и т. д.
В этой статье представлено новое программное обеспечение для расчета перекрывающихся областей, называемое SLDMS, инструмент, который использует данные секвенирования генов в качестве входных данных и поддерживает форматы fastq и fasta. Он может вычислять выходную информацию о перекрывающихся областях между данными секвенирования и записывать ее в файл, чтобы ее могли использовать другие приложения. По сравнению с другим программным обеспечением для сборки генома, которое вычисляет перекрывающиеся области, наш подход к проектированию на основе монотонного стека и массива суффиксов более эффективен и предоставляет более богатую информацию о пути для последующего программного обеспечения для сборки генома, которое можно использовать в качестве эталона. В то же время SLDMS можно легко интегрировать в процесс геномного анализа.
В то же время SLDMS можно легко интегрировать в процесс геномного анализа.
Методы
Общий рабочий процесс SLDMS (рис. 1) включает четыре этапа: (i) предварительная обработка данных; (ii) построение массива суффиксов; (iii) выбор версии программного обеспечения и создание соответствующей структуры данных; и (iv) обход массива суффиксов и вывод результатов перекрывающихся областей.
Рис. 1. Общий рабочий процесс SLDMS.
Структура данных
SLDMS требуется три массива при получении информации о перекрывающихся регионах. Эти три массива представляют собой массив суффиксных массивов (SA) (Manber and Myers, 1993) массив самого длинного общего префикса (LCP) (Fischer, 2010) и массив массива документов (DA) (Muthukrishnan, 2002). Сначала мы кратко представим эти три массива. Массив SA является массивом суффиксов, а SA(i) представляет начальную позицию суффикса, ранг строки которого равен i в исходной строке. Массив LCP является самым длинным массивом общих префиксов, а LCP(i) представляет собой самый длинный общий префикс суффиксов, представленных SA(i) и SA(i-1). Массив DA представляет собой массив документов. DA(i) представляет собой количество строк во входных данных, которым принадлежит суффикс ранга i. Этот массив можно получить в процессе получения SA и LCP.
Значение элементов, хранящихся в трех массивах, показано на рисунке 2. Массив SA: строка над массивом представляет собой суффикс, представленный каждым элементом в массиве, а значение, хранящееся в массиве, является начальной позицией суффикс, который он представляет в исходной строке. Массив LCP: строка над массивом представляет собой суффикс, представленный каждым элементом в массиве, а значение, хранящееся в массиве, представляет собой длину самого длинного общего префикса между суффиксом, который он представляет, и суффиксом, расположенным на одну позицию впереди него; чтобы вычислить эту длину, мы игнорируем конечные символы суффикса. Массив DA: строка над массивом представляет собой суффикс, представленный каждым элементом в массиве, а значение, хранящееся в массиве, является источником суффикса. Например, DA(i) = 20, «babbc» принадлежит 20-й входной последовательности.
Рисунок 2. Элементы хранятся в трех массивах.
Принцип алгоритма
Мы определяем чтение как фрагмент данных в данных секвенирования, а его представление в компьютере представляет собой строку. Прежде чем находить информацию о перекрывающихся областях данных секвенирования, сначала рассмотрим случай нахождения информации о перекрывающихся областях для двух чтений. Предположим, что два чтения — это str1 и str2; если конец строки str1 и начало строки str2 перекрываются, и перекрытие начинается в позиции i, то суффикс suf [suf = str1(i:)] строки str1 должен совпадать с некоторым префиксом строки str2. Другими словами, часть перекрытия является префиксом строки str2 (иначе строка str2 является подстрокой строки str1, а сращивание эквивалентно отбрасыванию строки str2, поэтому в этом случае нет необходимости склеивать строку str1 с строкой str2), поэтому самая длинная часть перекрытия из строк str1 и str2 должен быть суффиксом, принадлежащим строке str1, который стоит перед строкой str2 в порядке словаря. Информацию о перекрывающихся регионах можно получить, отсортировав все суффиксы строки str1 с помощью строки str2 и обработав суффиксы, расположенные перед строкой str2 (рис. 3). Как показано на Рисунке 3, набор суффиксов на Рисунке 3 не показывает суффиксы, принадлежащие str2, потому что чтение не может быть связано с самим собой, поэтому он вынесет суждение о принадлежности суффиксов и проигнорирует эти суффиксы, принадлежащие ему, при вычислении кандидата. ответы стр2.
Рис. 3. Позиция строки str2 в наборе суффиксов строки str1.
Расширить случай двух перекрывающихся операций чтения до набора операций чтения. Все суффиксы ридов сортируются, информация о наилучших областях перекрытия каждого рида должна существовать в каком-то ранжированном перед ним суффиксе, а рид, которому этот суффикс принадлежит, является максимально возможным смежным узлом текущего рида после построения графа.
Поскольку чтение само по себе также является суффиксом чтений, при обходе набора суффиксов, если мы встречаем определенное само чтение, мы можем гарантировать, что суффикс с информацией об его оптимальных перекрывающихся областях должен быть пройден. Тогда задача трансформируется в то, что самый длинный общий префикс, который вычисляется для всех ранжированных перед ним суффиксов и текущей строки, и когда длина общего префикса равна длине этого суффикса, мы рассматриваем этот суффикс как ответ-кандидат и выберите лучший или топ-K оптимальных ответов в качестве окончательного ответа среди всех ответов-кандидатов.
При разработке алгоритма мы выбираем две расширенные структуры данных, массив суффиксов и монотонный стек, поскольку информация, хранящаяся в массиве суффиксов, представляет собой суффикс строки, отсортированный в порядке словаря, который соответствует набору суффиксов на рис. 3. Причина выбора монотонного стека заключается в том, что монотонный стек может работать с массивом LCP для фильтрации набора суффиксов и удаления тех суффиксов, которые вряд ли будут ответом, и таким образом повысить скорость вычислений. Когда мы получаем определенный ответ-кандидат длиной x , остальные кандидаты с длиной больше x не должны точно совпадать с последующими чтениями; это связано с тем, что их общие префиксы имеют максимальную длину x , поэтому эти кандидаты должны быть удалены. Монотонный стек существует для удаления этой части информации.
Реализация
Построение массива SA, массива LCP и массива DA
Поскольку метод построения массивов SA и LCP в одной строке является достаточно зрелым, SLDMS объединяет все чтения данных в одну строку, разделение последовательности с кодом 1 Американского стандартного кода для обмена информацией (ASCII) и завершение сшивки с кодом ASCII 0. Это позволяет рассматривать набор считывания как строку, и мы называем эту объединенную сверхдлинную строку «исходной строкой». ». Для этой части мы используем программное обеспечение gsufsort (Louza et al., 2020), основанное на алгоритме gSACA-K (Louza et al., 2017), для получения трех массивов.
Поддержание монотонного стека
Предполагая, что количество операций чтения равно n , после получения информации о массиве SA и массиве LCP просматриваются первые n + 1 элементов массива SA. Эти n + 1 элементы являются позициями интервала $ между строками и символом конца строки # в исходной строке. Следовательно, мы можем получить начальную и конечную позиции каждого чтения в исходной строке и записать их в массив Fi и массив Se. Например, начальная позиция x-го считывания — Fi(x) = SA(X — 1) + 1, а конечная позиция — Se(x) = SA(x). В соответствии с начальной и конечной позицией каждого считывания его длина также рассчитывалась как LEN(x) = [SE(x) — Fi(x) + 1].
После получения приведенной выше информации процесс сопоставления суффиксов и чтений можно оптимизировать, поддерживая монотонный стек. Для разных входных данных применяются разные стратегии, и SLDMS была разработана в двух версиях. Первая версия считает данные полностью корректными и может напрямую выполнять расчет перекрывающихся областей. Точность результата зависит от входного набора данных, и если набор данных полностью правильный, результат также полностью правильный. Следовательно, входные данные, необходимые для использования этой версии, должны быть либо скорректированными данными высокой точности, либо необработанными данными высокой точности, такими как набор данных PacBio-HiFi (Hon et al. , 2020) и набор данных Sanger. Вторая версия допускает некоторые различия между чтениями при выполнении вычислений перекрывающихся областей. Информация о перекрывающихся областях может быть получена для данных с некоторыми ошибками, точность информации колеблется в зависимости от характеристик ошибок в данных, а точность результатов прогонов варьируется от одного набора данных к другому. После экспериментов было обнаружено, что точность результатов прогонов значительно повышается, когда ошибочная часть считываний собирается на обоих концах. Поэтому для второй версии, если ошибки в наборе данных полностью случайны, рекомендуется сначала исправить полные данные перед использованием первой версии или сначала исправить часть центра обработки данных перед использованием второй версии программного обеспечения.
Что касается исправления ошибок данных, мы предлагаем использовать данные секвенирования третьего поколения PacBio для исправления ошибок (Hon et al., 2020) или данные секвенирования Illumina второго поколения для исправления ошибок. данных секвенирования третьего поколения PacBio (Mahmoud et al., 2017), таких как PBCR (Koren et al., 2012) в знаменитом программном обеспечении Celera Assembler (Schatz, 2006; Denisov et al., 2008) и LoRDEC (Leena and Эрик, 2014) средство исправления ошибок. Для наборов данных с некоторой регулярностью ошибок данных (ошибки секвенирования проявляются с обеих сторон ридов) вторая версия этого программного обеспечения может быть выбрана напрямую.
данных секвенирования третьего поколения PacBio (Mahmoud et al., 2017), таких как PBCR (Koren et al., 2012) в знаменитом программном обеспечении Celera Assembler (Schatz, 2006; Denisov et al., 2008) и LoRDEC (Leena and Эрик, 2014) средство исправления ошибок. Для наборов данных с некоторой регулярностью ошибок данных (ошибки секвенирования проявляются с обеих сторон ридов) вторая версия этого программного обеспечения может быть выбрана напрямую.
Работа с считываниями без несоответствия
В этой версии, поскольку данные могут поддерживать высокую степень точности, достаточно напрямую получить информацию о перекрывающихся областях считываний, и проблема исправления ошибок чтений не затрагивается. Идея алгоритма заключается в следующем.
Построить монотонный стек. Стек реализован путем имитации массива, чтобы облегчить сбор данных в стеке. Тип элемента, хранящийся в стеке, представляет собой структуру, аналогичную разработанной нами паре. Его первый элемент имеет тип int, который используется для представления длины суффикса, хранящегося в текущем элементе. Его второй элемент представляет собой скользящий массив, который используется для хранения информации DA суффикса, удовлетворяющего первому условию. Длину массива можно задать искусственно; например, длина массива равна n , то есть хранить n лучших ответов для каждого чтения. Таким образом, мы можем получить больше перекрывающейся информации между чтениями. Структурный дизайн монотонного стека и элементов стека показан на дополнительном рисунке 1, где вектор — это структура стека, пара — это элемент, хранящийся в стеке, а очередь — это основная часть хранения информации в паре, которая реализована катящимся массивом (дополнительный рисунок 2).
Его второй элемент представляет собой скользящий массив, который используется для хранения информации DA суффикса, удовлетворяющего первому условию. Длину массива можно задать искусственно; например, длина массива равна n , то есть хранить n лучших ответов для каждого чтения. Таким образом, мы можем получить больше перекрывающейся информации между чтениями. Структурный дизайн монотонного стека и элементов стека показан на дополнительном рисунке 1, где вектор — это структура стека, пара — это элемент, хранящийся в стеке, а очередь — это основная часть хранения информации в паре, которая реализована катящимся массивом (дополнительный рисунок 2).
Поддерживайте монотонный стек (рис. 4А). Пусть один суффикс с рангом Y равен str, и для всех суффиксов с рангом до Y, если предположить, что их ранг равен X, их самый длинный общий префикс с str, т. е. длина LCP, должна быть равна min[LCP(X + 1:Y) ]. В соответствии с этим свойством при обходе массивов SA и LCP каждый раз при обходе нового LCP(i) элементы стека, первый элемент которых больше LCP(i), могут быть сняты со стека, поскольку для этих элементов и следующий суффикс LCP не может быть больше LCP(i), поэтому эти суффиксы становятся бесполезной информацией и могут быть очищены.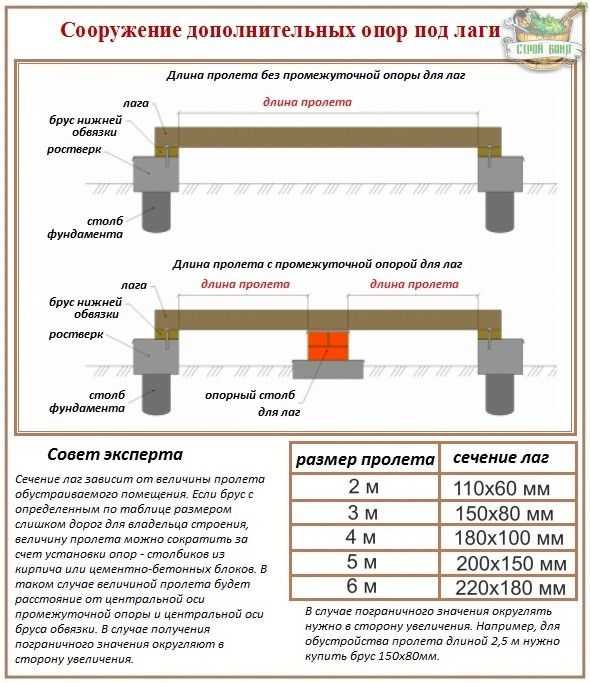 Начинайте работать с элементами монотонного стека с вершины стека; если первый элемент на вершине стека больше, чем LCP(x), просто извлеките этот верхний элемент из стека напрямую и зацикливайте эту операцию до тех пор, пока невозможно будет выбраться из стека. После очистки проверьте пару на вершине стека, равен ли ее первый элемент длине строки, соответствующей текущему SA(i) [len = se(DA(i) – SA(i))], если они равны, поместите DA(i) во второй массив прокрутки пары и обновите массив. Если он не равен, создайте новый элемент пары, первый из которых равен len и чьи начальные значения во втором элементе установлены следующим образом: голова = 0, хвост = 1, имеют = 1, размер = k и данные (0 ) = DA(i). После создания элемента этот элемент помещается в стек. Поскольку все элементы в стеке, первый из которых больше len, были удалены перед входом в стек, каждый элемент, входящий в стек, должен быть самым большим элементом в стеке, поэтому монотонность стека может быть гарантирована, что и является причиной для использования монотонного стека.
Начинайте работать с элементами монотонного стека с вершины стека; если первый элемент на вершине стека больше, чем LCP(x), просто извлеките этот верхний элемент из стека напрямую и зацикливайте эту операцию до тех пор, пока невозможно будет выбраться из стека. После очистки проверьте пару на вершине стека, равен ли ее первый элемент длине строки, соответствующей текущему SA(i) [len = se(DA(i) – SA(i))], если они равны, поместите DA(i) во второй массив прокрутки пары и обновите массив. Если он не равен, создайте новый элемент пары, первый из которых равен len и чьи начальные значения во втором элементе установлены следующим образом: голова = 0, хвост = 1, имеют = 1, размер = k и данные (0 ) = DA(i). После создания элемента этот элемент помещается в стек. Поскольку все элементы в стеке, первый из которых больше len, были удалены перед входом в стек, каждый элемент, входящий в стек, должен быть самым большим элементом в стеке, поэтому монотонность стека может быть гарантирована, что и является причиной для использования монотонного стека.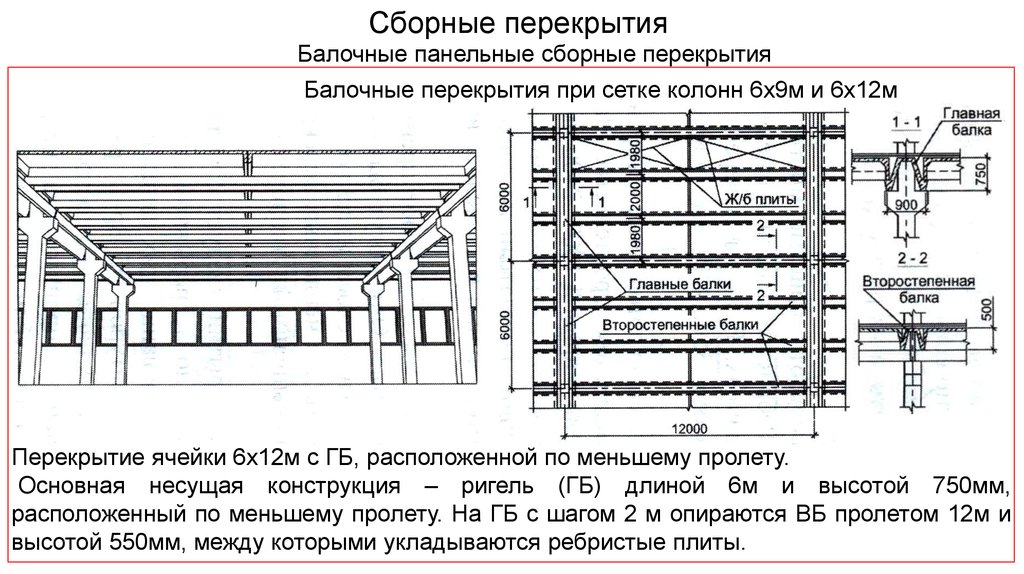
Рис. 4. (A) Схематическая диаграмма монотонного процесса обслуживания стека. (B) Схема процесса получения информации о перекрывающихся областях.
Получить информацию о перекрывающихся областях (рис. 4B). В процессе поддержания монотонного стека, если текущий суффикс является обычным суффиксом, просто следуйте обычному процессу поддержания монотонного стека, и если текущий суффикс является полным чтением [значение SA(i) равно fi( DA(i))], то к обычному процессу сопровождения следует добавить процесс получения информации; в это время вы можете сохранить монотонную информацию о стеке, чтобы получить требуемую информацию о перекрывающихся областях. Способ получения необходимой информации о перекрывающихся областях очень прост; прежде всего, мы должны сначала проверить вершину элементов стека, чтобы убедиться, что вершина элементов стека не просрочена (если срок действия элементов истек, их можно вынуть из стека). Затем прочитайте данные с вершины стека и прочитайте второй элемент каждого элемента; это операции чтения, которые с наибольшей вероятностью перекрываются с текущим чтением и выводят информацию о перекрывающихся областях в файл результатов для использования при построении графика весов ребер. По умолчанию предоставляются первые десять возможных результатов, обычно выбираются самые длинные перекрывающиеся области чтения, а конкретное чтение, выбранное в качестве пути на графе весов ребер, может быть свободно выбрано в соответствии с последующими требованиями к программному обеспечению.
По умолчанию предоставляются первые десять возможных результатов, обычно выбираются самые длинные перекрывающиеся области чтения, а конкретное чтение, выбранное в качестве пути на графе весов ребер, может быть свободно выбрано в соответствии с последующими требованиями к программному обеспечению.
Работа с считываниями с несоответствием
Данные секвенирования первого поколения являются высокоточными данными, но они больше не используются в массовом порядке из-за высокой стоимости секвенирования. Данные секвенирования второго поколения представляют собой короткие данные с высокой точностью и больше подходят для использования с программным обеспечением сборки DBG на основе подсчета K-меров (Wang et al., 2020), таким как SOAPdenovo (Xie et al., 2014) программного обеспечения. Данные секвенирования третьего поколения представляют собой данные длительного считывания с высокой частотой ошибок, и была бы высокая частота ошибок, если бы данные секвенирования были точно сопоставлены, поэтому эта версия допускает небольшие различия в последовательности в процессе сопоставления. Эта версия является альтернативным решением в ситуации, когда данные не могут быть полностью исправлены из-за длительного времени исправления или высокой стоимости исправления набора данных.
Эта версия является альтернативным решением в ситуации, когда данные не могут быть полностью исправлены из-за длительного времени исправления или высокой стоимости исправления набора данных.
В этой версии ошибочная часть входных данных должна отображаться на обоих концах данных, насколько это возможно, или часть центра обработки данных была исправлена, чтобы гарантировать отсутствие ошибок в средней части каждого чтения. Чем ближе местоположение ошибки к обоим концам, тем лучше будет информация о перекрывающихся областях. В этой версии будет введен параметр K, определяющий максимально допустимый размер вырезания начала и конца последовательности при согласовании алгоритма. Если K задан умозрительно, без особых знаний о наборе данных, в результате, полученном в результате одного прогона, может быть некоторая ошибка из-за параметров. Но скорость отказоустойчивого сопоставления очень высока, мы можем получить окончательный результат, введя разные отказоустойчивые параметры и запуская эту версию много раз. Мы также можем получить результат за один раз, точно установив K на основе знания распределения ошибок набора данных. Оптимальное значение K устанавливается таким образом, чтобы данные об ошибках на обоих концах могли быть исключены на основе как можно меньшего количества. Идея алгоритма заключается в следующем.
Мы также можем получить результат за один раз, точно установив K на основе знания распределения ошибок набора данных. Оптимальное значение K устанавливается таким образом, чтобы данные об ошибках на обоих концах могли быть исключены на основе как можно меньшего количества. Идея алгоритма заключается в следующем.
Построить монотонный стек. Монотонный стек в этой версии использует другую структуру, аналогичную паре. Его первый элемент хранит X символов во всех предыдущих чтениях в пределах диапазона отказоустойчивости, которые соответствуют текущему суффиксу. Этот первый элемент представляет X. Второй элемент больше не является скользящим массивом, а представляет собой порядковый номер суффикса с длиной X в массиве суффиксов в пределах диапазона отказоустойчивости. Окончательный результат получается путем сохранения и оптимизации всех вторых элементов в монотонном стеке, первые элементы которых больше, чем LCP(i). Концептуальная диаграмма монотонного стека показана на дополнительном рисунке 3.
Поддерживайте монотонный стек (рис. 5А). В отличие от предыдущей версии, если первый элемент на вершине стека больше, чем LCP(x), он не берет непосредственно элемент на вершине стека из стека, а удаляет все элементы стека, чьи первый элемент больше или равен LCP(x) и выбирает лучший элемент после сравнения, чтобы вернуться к вершине стека. Элемент, удовлетворяющий условию [len(STR) – LCP(x)], является лучшим и его первый элемент присваивается LCP(x), а второй элемент – второму оптимальному элементу. Этот процесс эквивалентен разрешению операции вырезания в конце чтения, когда неправильная часть вырезается и снова сопоставляется, а длина разрешенного вырезания устанавливается пользователем программного обеспечения. После обновления стека используйте информацию о текущем суффиксе для создания нового элемента пары. Если длина больше вершины стека, поместите его в стек. Если длина одинакова, замените верхнюю часть стека. Конечно, для предотвращения образования петель в графе, построенном из последней полученной информации о перекрывающихся областях, обновление стека выполняется путем игнорирования суффикса самого чтения.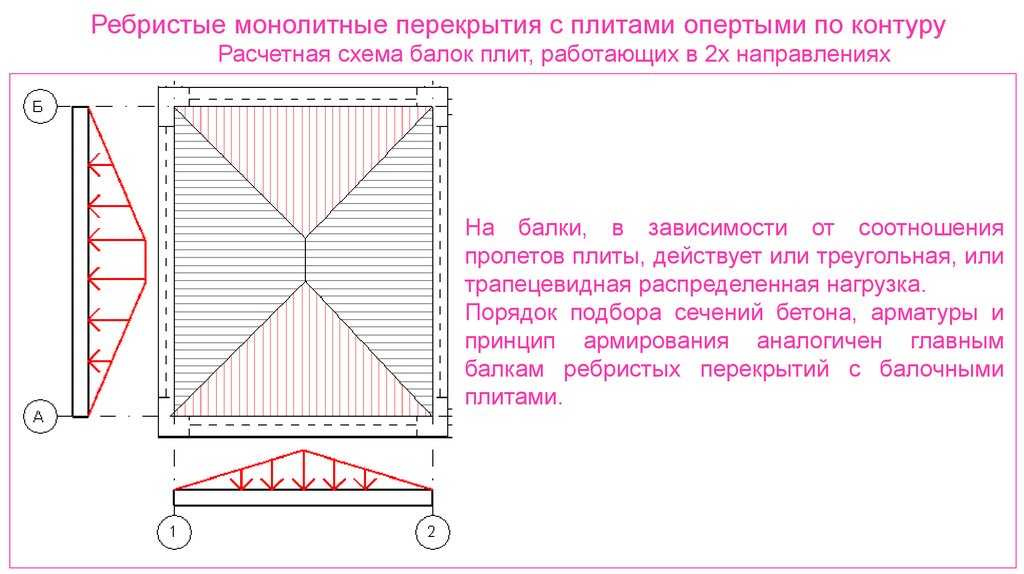
Рисунок 5. (A) Диаграмма процесса обслуживания монотонного стека и (B) Блок-схема сбора информации об областях перекрытия.
Получить информацию о перекрывающихся областях (рис. 5B). При обходе массива суффиксов в предыдущей версии результат получается только тогда, когда текущий суффикс является полным чтением. В этой версии результат получается, когда первый символ текущего суффикса является первым символом K исходной строки, но, конечно, K является определяемым, и эта операция эквивалентна разрешению вырезать заголовок данных последовательности и допустимая длина разреза равна K. Пробуется каждый метод разреза, так что каждое чтение сравнивается несколько раз и сохраняется максимально возможный результат. Следовательно, для множественных сравнений результатов необходимы два вспомогательных массива: массив ANS и массив LEN, где массив ANS хранит порядковый номер своего результата в массиве SA, а массив LEN хранит совпадающие длины. В процессе поддержания монотонного стека, если текущий суффикс является первым K суффиксов строки, которой он принадлежит, он сравнивается с верхним элементом стека и сохраняется лучший результат. Окончательный массив ANS получается после нескольких сеансов обслуживания. После обхода массива SA в этой версии результирующий DA[ANS(i)] представляет собой информацию об оптимальных перекрывающихся областях, которую необходимо получить.
В процессе поддержания монотонного стека, если текущий суффикс является первым K суффиксов строки, которой он принадлежит, он сравнивается с верхним элементом стека и сохраняется лучший результат. Окончательный массив ANS получается после нескольких сеансов обслуживания. После обхода массива SA в этой версии результирующий DA[ANS(i)] представляет собой информацию об оптимальных перекрывающихся областях, которую необходимо получить.
Поддерживать информацию о перекрывающихся регионах. Чтобы облегчить последующую сборку программного обеспечения, SLDMS предоставляет больше информации о перекрывающихся областях для последующего программного обеспечения. В этой версии для каждой последовательности также предоставляется набор суффиксов перекрытия top-k, чтобы облегчить последующую работу по сборке генома, и параметры необходимы для установки k перед запуском программного обеспечения. Структура данных, используемая для поддержания этого набора суффиксов, представляет собой минимальную кучу, а вершина кучи хранит K-е хорошие перекрывающиеся области (дополнительный рисунок 4). Причина выбора этой структуры данных заключается в том, что куча может эффективно поддерживать наибольшее или наименьшее значение в куче, поэтому создается минимальная куча емкостью K, а вершина кучи является наихудшим качеством ответа-кандидата, и когда встречается новый ответ-кандидат, его нужно только сравнить с вершиной кучи, что облегчает обновление ответа.
Причина выбора этой структуры данных заключается в том, что куча может эффективно поддерживать наибольшее или наименьшее значение в куче, поэтому создается минимальная куча емкостью K, а вершина кучи является наихудшим качеством ответа-кандидата, и когда встречается новый ответ-кандидат, его нужно только сравнить с вершиной кучи, что облегчает обновление ответа.
Метод обслуживания информации о перекрывающихся регионах: создание минимальной кучи для каждого чтения для поддержания набора суффиксов top-k, данные в куче сохраняют положение соответствующего суффикса в массиве SA, а Len сохраняет совпадающую длину между суффикс и текущее чтение. Узел (1) соответствует вершине кучи. Чем больше размер кучи, тем больше информации получается и тем дольше выполняется соответствующая программа. Для получения требуемой информации верхний элемент стека сравнивается с данными в min-куче, помимо сохранения оптимального значения массива ans, при обходе массива суффиксов и встрече с суффиксом, который может получить ответ [ i-fi(da(i)) ≤ k]. Если количество данных в минимальной куче меньше k, поместите верхний элемент стека непосредственно в минимальную кучу и обновите кучу снизу вверх (рис. 6А). Это связано с тем, что емкость кучи равна K. В куче все еще есть место для хранения ответов-кандидатов, поэтому ответы-кандидаты могут быть помещены непосредственно в кучу, а куча может быть обновлена. В противном случае сравните верхний элемент стека с верхним элементом кучи. Если верхний элемент кучи лучше, не обновляйте элементы в куче; в противном случае используйте верхний элемент стека для замены верхнего элемента кучи и обновления кучи сверху вниз (рис. 6B). Это связано с тем, что в куче нет места для хранения дополнительных ответов-кандидатов, поэтому мы должны выбирать между ответами K в куче и текущими ответами-кандидатами и удалять ответ наихудшего качества. Используя этот метод, пользователи программного обеспечения могут получить больше информации о перекрывающихся областях, что делает график веса ребер на основе этой информации о перекрытии более качественной информацией для облегчения последующей обработки программного обеспечения.
Если количество данных в минимальной куче меньше k, поместите верхний элемент стека непосредственно в минимальную кучу и обновите кучу снизу вверх (рис. 6А). Это связано с тем, что емкость кучи равна K. В куче все еще есть место для хранения ответов-кандидатов, поэтому ответы-кандидаты могут быть помещены непосредственно в кучу, а куча может быть обновлена. В противном случае сравните верхний элемент стека с верхним элементом кучи. Если верхний элемент кучи лучше, не обновляйте элементы в куче; в противном случае используйте верхний элемент стека для замены верхнего элемента кучи и обновления кучи сверху вниз (рис. 6B). Это связано с тем, что в куче нет места для хранения дополнительных ответов-кандидатов, поэтому мы должны выбирать между ответами K в куче и текущими ответами-кандидатами и удалять ответ наихудшего качества. Используя этот метод, пользователи программного обеспечения могут получить больше информации о перекрывающихся областях, что делает график веса ребер на основе этой информации о перекрытии более качественной информацией для облегчения последующей обработки программного обеспечения.
Рисунок 6. Схема процесса обновления min-heap: (A) снизу вверх и (B) сверху вниз.
Вывод окончательного результата перекрывающихся областей
Программное обеспечение SLDMS строит график весов ребер со считыванием в качестве точки и информацией о перекрывающихся областях в качестве ребра на основе информации о перекрытии после получения информации о перекрывающихся областях, которая содержит информацию о положении перекрытия два чтения в дополнение к длине перекрытия для использования при получении начального контига. Каждый путь в графе сшивается в более длинное чтение в соответствии с информацией о перекрывающихся областях, которая является начальным контигом, и программное обеспечение SLDMS сохраняет всю информацию в этом графе весов ребер в файл для следующего шага получения контига.
При обработке чтений без несоответствия SLDMS подсчитывает информацию о перекрывающихся областях только при обнаружении полного чтения, полное чтение встречается только один раз, и результат не обновляется снова в последующем процессе обслуживания, поэтому вывод в файл находится в порядке встречающихся чтений, что является способом синхронного обновления обработки данных и вывода результатов. При обработке чтений с несоответствием SLDMS собирает данные для чтения несколько раз в процессе поддержания монотонного стека, поэтому сохраненная информация о результатах может быть обновлена последующим обслуживанием, и принимается идея дизайна программы, предусматривающая разделение обработки данных и вывода результатов. Для обеспечения точности результатов поддерживаемые результаты выводятся в порядке входных данных после того, как программа обработает все данные.
При обработке чтений с несоответствием SLDMS собирает данные для чтения несколько раз в процессе поддержания монотонного стека, поэтому сохраненная информация о результатах может быть обновлена последующим обслуживанием, и принимается идея дизайна программы, предусматривающая разделение обработки данных и вывода результатов. Для обеспечения точности результатов поддерживаемые результаты выводятся в порядке входных данных после того, как программа обработает все данные.
Хотя выходные данные двух стратегий различаются, логически обе они заполняют массив конечных результатов, и i-й элемент этого массива хранит ответ i-го чтения. Эти две стратегии отличаются только порядком заполнения массива, один заполняет массив по порядку, а другой заполняет массив в беспорядке, но конечная цель состоит в том, чтобы заполнить массив полностью.
Анализ точности
Чтобы доказать универсальность программного обеспечения SLDMS, мы напишем программу для случайной генерации смоделированной последовательности генов, многократного обхода сгенерированной последовательности генов и случайного выбора подстроки для секвенирования смоделированного гена. В первой версии подстрока полностью корректна, а во второй версии случайные ошибки генерируются на обоих концах подстроки и используются для ввода программного обеспечения SLDMS. В то же время мы записываем начальную и конечную позиции каждого чтения и сохраняем их в контрольном файле для окончательной проверки точности.
В первой версии подстрока полностью корректна, а во второй версии случайные ошибки генерируются на обоих концах подстроки и используются для ввода программного обеспечения SLDMS. В то же время мы записываем начальную и конечную позиции каждого чтения и сохраняем их в контрольном файле для окончательной проверки точности.
Мы считаем, что результат каждого считывания правильный, если он относится к соседнему чтению в последовательности гена. После использования программного обеспечения SLDMS для запуска этих входных данных выходной файл и контрольный файл объединяются для подтверждения точности. По результатам в выходном файле определяли, есть ли общая часть в интервале двух чтений в контрольном файле. Если есть общая часть, значит, два рида должны быть собраны вместе. Мы считаем, что это правильный результат. Пишем программу для выполнения этой работы. Сначала программа читает выходной файл и проверочный файл; найти каждую пару чтений и соответствующую информацию о перекрывающихся областях в выходном файле (если длина перекрытия меньше 100, она считается недопустимыми данными и отбрасывается напрямую), а затем найти соответствующий интервал в контрольном файле и проверить интервал. Если в двух интервалах есть общая часть, мы можем найти соответствующий интервал в контрольном файле, который считается правильным результатом. После расчета точность двух версий SLDMS выше 99,99%.
Если в двух интервалах есть общая часть, мы можем найти соответствующий интервал в контрольном файле, который считается правильным результатом. После расчета точность двух версий SLDMS выше 99,99%.
Само программное обеспечение SLDMS и программный код, используемый в вышеуказанном процессе проверки точности, хранятся на веб-сайте GitHub по адресу https://github.com/Dongliang-You/sldms.
Результаты
SLDMS и программное обеспечение Flye and Canu были протестированы на 6 наборах данных PacBio-HiFi разного размера и секвенированных видов и 32 смоделированных наборах данных (16 наборов данных сверхвысокой точности и 16 наборов данных с ошибками на обоих концах считывания) на настольный компьютер с процессором Intel Core (TM) i7-9700 (8-ядерный процессор с частотой 3,00 ГГц), 32 ГБ ОЗУ и 477 ГБ на жестком диске. Из-за ограниченных аппаратных условий тестовой среды набор данных большого размера был сокращен, где описания набора данных PacBio-HiFi показаны в таблице 1, которые представляют собой наборы данных, загруженные с официального веб-сайта Национального центра биотехнологической информации (NCBI). Прогоны чтения последовательности (SRR) в описании представляют собой запись данных набора данных на веб-сайте, а конкретную информацию о данных можно просмотреть на официальном веб-сайте NCBI в соответствии с информацией о записи данных, которая находится по адресу https:// www.ncbi.nlm.nih.gov/. Информация о данных смоделированного набора данных показана в дополнительных таблицах 1, 2.
Прогоны чтения последовательности (SRR) в описании представляют собой запись данных набора данных на веб-сайте, а конкретную информацию о данных можно просмотреть на официальном веб-сайте NCBI в соответствии с информацией о записи данных, которая находится по адресу https:// www.ncbi.nlm.nih.gov/. Информация о данных смоделированного набора данных показана в дополнительных таблицах 1, 2.
Таблица 1. Набор данных PacBio-HiFi, использованный в эксперименте, и его описание.
Отсчет времени в эксперименте начинается, когда считываются данные секвенирования, и заканчивается, когда контиг готов к получению. Это означает, что необходимо иметь возможность построить граф веса ребер из информации о перекрывающихся областях, чтобы получить контиг.
Для версий SLDMS, не допускающих несоответствия, для тестирования и сравнения с программным обеспечением Canu и Flye были выбраны шесть наборов данных PacBio-HiFi с 16 смоделированными наборами данных высокой точности. При запуске ПО Flye параметр genomeSize является наилучшей оценкой согласно документации uasge.md ПО Flye, что составляет примерно 1% от размера файла. Параметр минимального перекрытия установлен на 1000, а остальные параметры являются параметрами по умолчанию. При запуске программного обеспечения Canu параметр genomeSize представляет собой наилучшее предполагаемое значение, введенное в соответствии с документацией по использованию, которое совпадает с параметром genomeSize программного обеспечения Flye, а остальные параметры являются значениями по умолчанию без каких-либо ограничений.
При запуске ПО Flye параметр genomeSize является наилучшей оценкой согласно документации uasge.md ПО Flye, что составляет примерно 1% от размера файла. Параметр минимального перекрытия установлен на 1000, а остальные параметры являются параметрами по умолчанию. При запуске программного обеспечения Canu параметр genomeSize представляет собой наилучшее предполагаемое значение, введенное в соответствии с документацией по использованию, которое совпадает с параметром genomeSize программного обеспечения Flye, а остальные параметры являются значениями по умолчанию без каких-либо ограничений.
Время, необходимое различным программам для запуска наборов данных PacBio-HiFi для поиска перекрывающихся областей, показано на рисунке 7 и в дополнительной таблице 3. Программное обеспечение SLDMS работало быстрее, чем Flye, на всех наборах данных, быстрее, чем Canu, на большинстве наборов данных. и лишь немного медленнее, чем программное обеспечение Canu в наборе данных M. musculus _part1, из-за характера алгоритма программного обеспечения Canu, который делает его потенциально эффективным при работе с определенными наборами данных. Этот результат предполагает, что программное обеспечение SLDMS работает более эффективно, чем Canu и Flye, для выравнивания последовательностей в большинстве наборов данных PacBio-HiFi.
Этот результат предполагает, что программное обеспечение SLDMS работает более эффективно, чем Canu и Flye, для выравнивания последовательностей в большинстве наборов данных PacBio-HiFi.
Рисунок 7. Время, необходимое различным программам для запуска наборов данных PacBio-HiFi для поиска перекрывающихся областей.
Время, необходимое различным программам для запуска наборов данных моделирования сверхвысокой точности для поиска перекрывающихся областей, показано на рисунках 8, 9 и в дополнительной таблице 4. Как показано на двух линейных графиках в первой строке рисунка 8, это результаты запуска набора данных моделирования сверхвысокой точности с различной средней длиной для одного и того же объема данных 5 000, 10 000, 15 000 и 20 000 чтений. Как показано на двух линейных графиках во второй строке рисунка 8, это результаты запуска набора данных моделирования сверхвысокой точности с различными объемами данных для одной и той же средней длины данных 5000, 10000, 15000 и 20000. Как видно из графиков во всех запусках, программное обеспечение SLDMS имеет более короткое время выполнения, чем два других, что говорит о том, что в большинстве случаев использование программного обеспечения SLDMS является хорошим выбором для поиска информации о перекрывающихся областях.
Как видно из графиков во всех запусках, программное обеспечение SLDMS имеет более короткое время выполнения, чем два других, что говорит о том, что в большинстве случаев использование программного обеспечения SLDMS является хорошим выбором для поиска информации о перекрывающихся областях.
Рис. 8. Время, необходимое различным программам для выполнения высокоточных наборов данных моделирования для поиска перекрывающихся областей.
Рисунок 9. Время, необходимое разным программам для запуска наборов данных моделирования с ошибками для поиска перекрывающихся областей.
Для версий SLDMS, которые допускают несоответствие, отсутствуют реальные данные, соответствующие условиям запуска этой версии, поэтому эту версию можно было протестировать только с использованием смоделированных данных. Каждое чтение смоделированных данных было разделено на три части по порядку, при этом первая и третья части имели точность 80%, вторая часть была точна на 100%, а вторая часть составляла не менее половины длины чтения. Программное обеспечение Canu и Flye выбрало PacBio-Raw в качестве типа данных во время тестов, а остальные настройки параметров были такими же, как и в предыдущей версии.
Программное обеспечение Canu и Flye выбрало PacBio-Raw в качестве типа данных во время тестов, а остальные настройки параметров были такими же, как и в предыдущей версии.
Время, необходимое различным программам для запуска наборов данных моделирования с ошибками для поиска перекрывающихся областей, показано на рисунке 9, где строка 1 представляет собой эксперимент со средней длиной данных в качестве переменной, а строка 2 представляет собой эксперимент с количество данных в качестве переменной. Как видно из графика, при запуске этих наборов данных, как при запуске наборов данных с разной средней длиной для одного и того же объема данных, так и при запуске наборов данных с разным объемом данных для одной и той же средней длины, SLDMS работает намного быстрее, чем два других. Это показывает, что использование SLDMS для запуска этого набора данных с ошибками только на обоих концах данных намного лучше и занимает меньше времени, чем использование двух других программных инструментов.
В ходе эксперимента мы проверили производительность различных программ на разных наборах данных. Программное обеспечение SLDMS было стабильным и эффективным при получении информации о перекрывающихся областях для различных тестовых данных. Время работы SLDMS зависит только от размера входного набора данных и не зависит от различий в точности данных. Это означает, что SLDMS подходит для обработки широкого спектра данных, не беспокоясь о том, что SLDMS потребуется особенно много времени для обработки определенного типа данных.
Программное обеспечение SLDMS использует алгоритм gsufsort для расчета трех массивов информации SA, LCP и DA, что занимает значительное время. Если будут разработаны новые методы для более быстрого получения этой информации, программное обеспечение SLDMS будет более эффективным.
Обсуждение
Основной вклад предлагаемого метода SLDMS для извлечения информации о перекрывающихся областях между последовательностями на основе массивов суффиксов и монотонных стеков заключается в существенном улучшении временной эффективности вычисления перекрывающихся областей.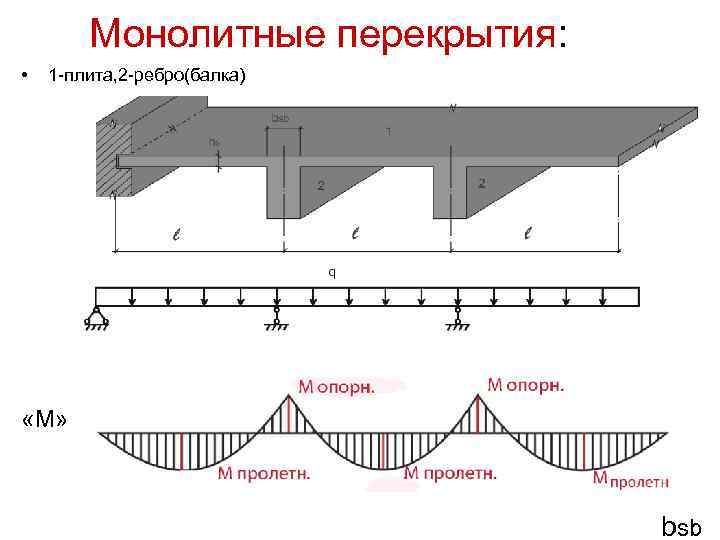 Получение информации о перекрывающихся областях полезно во многих приложениях биоинформатики. По мере снижения стоимости технологии секвенирования и развития технологии секвенирования генома становится проще получать данные секвенирования с широким диапазоном характеристик и более высокой точностью. При сборке этих данных секвенирования важно эффективно извлекать информацию о перекрывающихся областях между последовательностями, чтобы обеспечить более благоприятную среду для последующей работы по сборке генома.
Получение информации о перекрывающихся областях полезно во многих приложениях биоинформатики. По мере снижения стоимости технологии секвенирования и развития технологии секвенирования генома становится проще получать данные секвенирования с широким диапазоном характеристик и более высокой точностью. При сборке этих данных секвенирования важно эффективно извлекать информацию о перекрывающихся областях между последовательностями, чтобы обеспечить более благоприятную среду для последующей работы по сборке генома.
Программное обеспечение Flye использует алгоритм ABruijn, который объединяет алгоритмы OLC и DBG для создания собственного уникального графа ABG, получает информацию о перекрывающихся областях узлов в графе, а затем обрабатывает граф ABG для получения контигов. В этом процессе обработка графика занимает значительное время, поэтому из экспериментальных результатов видно, что программное обеспечение Flye работает примерно в два раза дольше, чем SLDMS, почти на всех наборах данных.
Программное обеспечение Canu использует алгоритм MHAP для объединения считываний с одним и тем же k-мером для исправления ошибок и сокращения, а затем получает информацию о перекрывающихся областях. При работе с высокоточными данными без исправления ошибок SLDMS примерно на 20% быстрее, чем Canu. Что касается исправления ошибок, программное обеспечение Canu работает очень медленно, независимо от характеристик ошибок данных, что указывает на то, что программное обеспечение Canu не использует в полной мере характеристики ошибок данных. SLDMS делает очень хорошую работу в этом отношении, и в некоторых данных с большинством ошибок секвенирования возникает на обоих концах данных секвенирования, SLDMS работает во много раз быстрее, чем Canu.
SLDMS получает три массива SA, LCP и DA путем обработки входных данных и быстро находит информацию о перекрывающихся областях во входных данных с помощью этих трех массивов и монотонного стека. Улучшена скорость вычисления информации о перекрывающихся областях.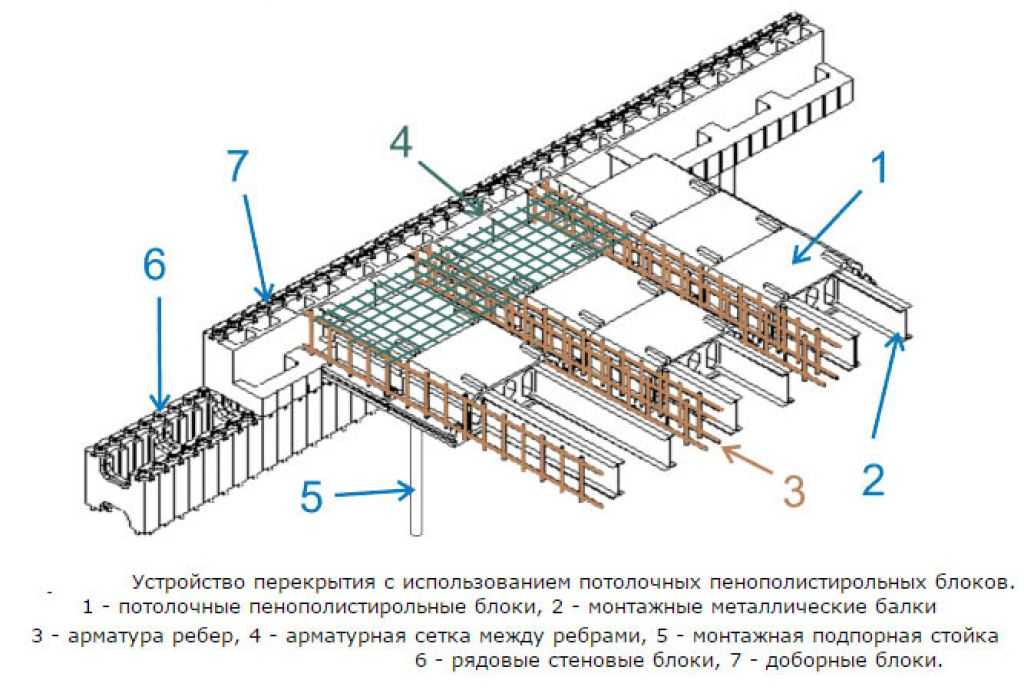 Экспериментальные результаты показывают, что по сравнению с двумя другими типами программного обеспечения SLDMS имеет более высокую скорость при расчете перекрывающихся областей, а с помощью массива SA, содержащего все суффиксы, он также имеет возможность отказоустойчивости данных путем вырезания суффиксы. Это показывает, что SLDMS очень эффективен как подход, основанный на массивах суффиксов и монотонных стеках, и что массивы суффиксов по-прежнему являются идеальной структурой данных для решения проблемы вычисления перекрывающихся областей последовательностей генов.
Экспериментальные результаты показывают, что по сравнению с двумя другими типами программного обеспечения SLDMS имеет более высокую скорость при расчете перекрывающихся областей, а с помощью массива SA, содержащего все суффиксы, он также имеет возможность отказоустойчивости данных путем вырезания суффиксы. Это показывает, что SLDMS очень эффективен как подход, основанный на массивах суффиксов и монотонных стеках, и что массивы суффиксов по-прежнему являются идеальной структурой данных для решения проблемы вычисления перекрывающихся областей последовательностей генов.
О SLDMS
SLDMS — это программный инструмент с открытым исходным кодом, разработанный на C, и его можно запускать только в системах Linux. Ссылка на проект (https://github.com/Dongliang-You/sldms). Перед использованием в неакадемических целях требуется разрешение автора.
Заявление о доступности данных
Наборы данных, представленные в этом исследовании, можно найти в онлайн-репозиториях.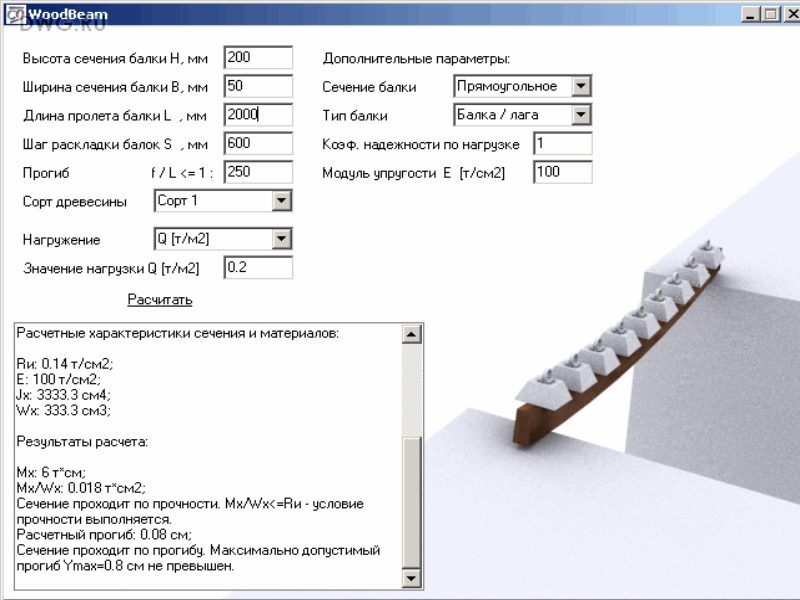 Названия репозитория/репозиториев и регистрационные номера можно найти ниже: https://bioinfor.nefu.edu.cn/chenyu/sldms_web/, sldms.
Названия репозитория/репозиториев и регистрационные номера можно найти ниже: https://bioinfor.nefu.edu.cn/chenyu/sldms_web/, sldms.
Вклад авторов
YC: концептуализация. ДЯ: программное обеспечение. GW: написание – первоначальный вариант. ТЗ: написание – рецензирование и редактирование. Все авторы проводили эксперименты, читали и соглашались с опубликованной версией рукописи.
Финансирование
Это исследование было поддержано Национальным фондом естественных наук Китая (61771165, 62072095 и 62172087), Национальной ключевой программой исследований и разработок Китая (2021YFC2100100), Фондами фундаментальных исследований для центральных университетов (2572021BH01) и Инновационный проект Государственной ключевой лаборатории генетики и селекции деревьев Северо-Восточного лесотехнического университета (2019 г.)А04).
Конфликт интересов
Авторы заявляют, что исследование проводилось при отсутствии каких-либо коммерческих или финансовых отношений, которые могли бы быть истолкованы как потенциальный конфликт интересов.
Примечание издателя
Все утверждения, изложенные в этой статье, принадлежат исключительно авторам и не обязательно представляют претензии их дочерних организаций или издателя, редакторов и рецензентов. Любой продукт, который может быть оценен в этой статье, или претензии, которые могут быть сделаны его производителем, не гарантируются и не поддерживаются издателем.
Дополнительный материал
Дополнительный материал к этой статье можно найти в Интернете по адресу: https://www.frontiersin.org/articles/10.3389/fpls.2021.813036/full#supplementary-material
Список литературы
Денисов Г. , Валенц, Б., Халперн, А.Л., Миллер, Дж., Аксельрод, Н., Леви, С., и соавт. (2008). Генерация консенсуса и обнаружение вариантов с помощью Celera Assembler. Биоинформатика 2008:btn074. doi: 10.1093/bioinformatics/btn074
PubMed Abstract | Полный текст перекрестной ссылки | Академия Google
Фишер, Дж. (2010). Ви ЛКП. Инф. Обработка письма. 110, 317–320. doi: 10.1016/j.ipl.2010.02.010
110, 317–320. doi: 10.1016/j.ipl.2010.02.010
CrossRef Полный текст | Google Scholar
Достопочтенный Т., Марс К., Янг Г., Цай Ю. К. и Ранк Д. Р. (2020). Высокоточные данные секвенирования с длительным чтением HiFi для пяти сложных геномов. Науч. Данные 7:077180. doi: 10.1101/2020.05.04.077180
CrossRef Полный текст | Google Scholar
Хуанг, X. (1992). Программа сборки contig, основанная на чувствительном обнаружении перекрытий фрагментов. Геномика 14, 18–25. doi: 10.1016/S0888-7543(05)80277-0
Полный текст CrossRef | Google Scholar
Корен С., Шац М. К., Валенц Б. П., Мартин Дж., Ховард Дж. Т., Ганапати Г. и др. (2012). Гибридная коррекция ошибок и сборка de novo считываний секвенирования одной молекулы. Нац. Биотехнолог. 30, 693–700. doi: 10.1038/nbt.2280
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Корен С., Валенц Б. П., Берлин К., Миллер Дж. Р., Бергман Н. Х. и Филлиппи А. М. (2017). Canu: масштабируемая и точная сборка с длительным чтением с помощью адаптивного взвешивания k-меров и разделения повторов. Рез. генома. 27, 722–736. doi: 10.1101/gr.215087.116
М. (2017). Canu: масштабируемая и точная сборка с длительным чтением с помощью адаптивного взвешивания k-меров и разделения повторов. Рез. генома. 27, 722–736. doi: 10.1101/gr.215087.116
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Лина С. и Эрик Р. (2014). LoRDEC: точное и эффективное исправление ошибок длительного чтения. Биоинформатика 30, 3506–3514. doi: 10.1093/bioinformatics/btu538
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Ли, З. (2012). Сравнение двух основных классов алгоритмов сборки: перекрытие-макет-консенсус и дебрейн-граф. Кратко. Функц. Геном. 11, 25–37. doi: 10.1093/bfgp/elr035
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Лин Ю., Юань Дж., Колмогоров М., Шен М. В., Чейссон М. и Певзнер П. А. (2016). Сборка длинных, подверженных ошибкам операций чтения с использованием графов де Брейна. Про. Натл. акад. науч. США 113:E8396. doi: 10.1073/pnas.1604560113
doi: 10.1073/pnas.1604560113
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Луза Ф. А., Гог С. и Теллес Г. П. (2017). Создание расширенных массивов суффиксов для коллекций строк. Теор. вычисл. науч. 678, 22–39. doi: 10.1016/j.tcs.2017.03.039
CrossRef Полный текст | Google Scholar
Луза Ф. А., Теллес Г. П., Гог С., Прецца Н. и Розоне Г. (2020). gsufsort: создание массивов суффиксов, массивов LCP и BWT для коллекций строк. Алгоритмы Мол. биол. 15:18. doi: 10.1186/s13015-020-00177-y
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Махмуд М., Живицки М., Твардовски Т. и Карловски В. М. (2017). Эффективность коррекции длинных прочтений pacbio с помощью секвенирования Illumina 2-го поколения. Геномика 2017:S0888754317301660. doi: 10.1016/j.ygeno.2017.12.011
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Манбер, У., и Майерс, Г. (1993). Массивы суффиксов: новый метод поиска строк в режиме онлайн. СИАМ Дж. Вычисл. 22, 935–948. doi: 10.1137/0222058
Массивы суффиксов: новый метод поиска строк в режиме онлайн. СИАМ Дж. Вычисл. 22, 935–948. doi: 10.1137/0222058
CrossRef Полный текст | Google Scholar
Мутукришнан, С. (2002). Эффективные алгоритмы для задач поиска документов. Проц. СОДА 2002, 657–666.
Google Scholar
Шац, М. (2006). Ассемблер Celera Обзор ассемблера Celera. Гонолулу, Гавайи: Гавайский университет.
Google Scholar
Ван Дж., Чен С., Донг Л. и Ван Г. (2020). Chtkc: надежный и эффективный алгоритм подсчета k-меров, основанный на цепочке хэш-таблиц без блокировок. Краткая информация. Биоинформ. 22:ббаа063. doi: 10.1093/bib/bbaa063
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Xie, Y., Wu, G., Tang, J., Luo, R., Jordan, P., Liu, S., et al. (2014). SOAPdenovo-Trans: сборка транскриптома de novo с короткими считываниями RNA-Seq. Биоинформатика 12:1660. doi: 10.1093/bioinformatics/btu077
PubMed Abstract | Полный текст перекрестной ссылки | Google Scholar
Расчет перекрытия домашнего диапазона с помощью amt
Расчет перекрытия домашнего диапазона с помощью amtЙоханнес Сигнер и Джон Фиберг
22.
 02.2022
02.2022История вопроса
Было предложено несколько различных индексов для измерения перекрытия домашнего диапазона. Они рассмотрены Fieberg & Kochany (2005) 1 . Существует два общих подхода, используемых для расчета перекрытия домашнего диапазона: 1) вычисление процентного перекрытия на заданном уровне изоплеты (это работает для геометрических и вероятностных домашних диапазонов) или 2) вычисление индекса сходства между двумя распределениями использования (UD; это работает только для вероятностных оценок) 2 .
Реализация в
amt amt в настоящее время реализует все методы расчета перекрытий, рассмотренные Fieberg and Kochany (2005). Это:
-
hr: Это доля домашнего диапазона экземпляра \(i\), которая перекрывается с домашним диапазоном экземпляра \(j\). Эта мера не зависит от UD и является направленной (т. е. \(HR_{i,j} \ne HR_{j,i}\)) и ограничена между 0 (нет перекрытия) и 1 (полное перекрытие) -
phr: Вероятность того, что экземпляр \(j\) находится в домашнем диапазоне экземпляра \(i\).
phrтакже является направленным и ограничен между 0 (без перекрытия) и 1 (полное перекрытие) -
vi: Объемное пересечение двух UD. -
ba: Сродство Бхаттачарьи между двумя UD. -
udoi: Индекс перекрытия UD. -
hd: Расстояние Хеллингера между двумя UD.
Эти индексы перекрытия можно рассчитать с помощью функции hr_overlap . Тип измерения перекрытия можно контролировать с помощью аргумента типа .
Все эти оценщики могут быть рассчитаны для заданного уровня домашнего диапазона (т. е. с использованием условных UD). Желателен или нет условный перекрытие, можно контролировать с помощью аргумента условного . Для hr аргумент условное не действует, и изоплеты, используемые для оценки домашнего диапазона, всегда будут использоваться для вычисления перекрытия.
Функция hr_overlap() также может быть снабжена списком оценок домашнего диапазона в ситуациях, когда требуется перекрытие между многими различными экземплярами. В настоящее время существует три варианта вычисления перекрытия между несколькими экземплярами:
В настоящее время существует три варианта вычисления перекрытия между несколькими экземплярами: = «все» вычисляет перекрытие для каждой пары домашних диапазонов, = «один_ко_всем» вычисляет перекрытие между первым элементом в списке и всеми остальными, и , который = "последовательный" будет вычислять перекрытие между последовательными элементами в списке.
Примеры
Сначала нам нужно загрузить необходимые пакеты:
библиотека(амт) библиотека (ggplot2) библиотека (tidygraph) library(ggraph)
Два экземпляра
Мы будем использовать данные отслеживания от Fishers из штата Нью-Йорк, США.
лерой <- amt_fisher %>% filter(name == "Leroy") lupe <- amt_fisher %>% filter(name == "Lupe")
Создать шаблон растра для KDE
trast <- make_trast(amt_fisher %>% filter(name %in% c("Leroy", "Lupe ")), рез = 50) И оценить домашние дальности для обоих рыбаков
hr_leroy <- hr_kde(leroy, trast = trast, level = c(0.5, 0.9)) hr_lupe <- hr_kde(lupe, trast = trast, level = c(0.5, 0.9))
hr и phr являются направленными, это означает, что порядок имеет значение. Для всех других мер перекрытия порядок не имеет значения.
hr_overlap(hr_leroy, hr_lupe, type = "hr")
## # Набор символов: 2 × 2 ## уровни перекрываются #### 1 0,90,309 ## 2 0.5 0.191
hr_overlap(hr_lupe, hr_leroy, type = "hr")
## # tibble: 2 × 2 ## уровни перекрываются #### 1 0,9 0,986 ## 2 0.5 0.574
По умолчанию условно = ЛОЖЬ и используется полный UD.
hr_overlap(hr_leroy, hr_lupe, type = "phr", Conditional = FALSE)
## # Набор символов: 1 × 2 ## уровни перекрываются #### 1 1 1
hr_overlap(hr_lupe, hr_leroy, type = "phr", условное = FALSE)
## # Буквы: 1 × 2 ## уровни перекрываются #### 1 1 0,723
Если мы установим conditional = TRUE , перекрытие измеряется на уровнях домашнего диапазона, которые были указаны во время оценки.
hr_overlap(hr_leroy, hr_lupe, type = "phr", Conditional = TRUE)
## # Набор символов: 2 × 2 ## уровни перекрываются #### 1 0,5 0,582 ## 2 0.9 0.992
hr_overlap(hr_lupe, hr_leroy, type = "phr", Conditional = TRUE)
## # Тиббл: 2 × 2 ## уровни перекрываются #### 1 0,5 0,221 ## 2 0,9 0,401
Обратите внимание, что для остальных мер перекрытия порядок не имеет значения. Ниже мы покажем это для объемного пересечения ( type = "vi" ) в качестве примера.
hr_overlap(hr_lupe, hr_leroy, type = "vi", условное = FALSE)
## # Набор символов: 1 × 2 ## уровни перекрываются #### 1 1 0.439
hr_overlap(hr_leroy, hr_lupe, type = "vi", условное = FALSE)
## # Буквы: 1 × 2 ## уровни перекрываются #### 1 1 0.439
\(> 2\) instances
Давайте рассчитаем дневные диапазоны для Lupe и затем посмотрим, как разные диапазоны пересекаются друг с другом.
Мы должны использовать один и тот же шаблонный растр, чтобы сделать диапазоны сопоставимыми.
trast <- make_trast(lupe, res = 50)
Затем мы добавляем новый столбец с днем и вычисляем для каждого дня домашний диапазон KDE .
дата <- лупе %>% mutate(week = lubridate::floor_date(t_, "week")) %>% гнездо (данные = - неделя) %>% mutate(kde = map(data, hr_kde, trast = trast, level = c(0,5, 0,95, 0,99)))
Теперь мы можем использовать столбец списка с оценками домашнего диапазона для расчета перекрытия между различными домашними диапазонами . По умолчанию = "последовательный" , это означает, что для каждой записи списка (= оценка исходного диапазона) будет вычисляться перекрытие следующей записи.
hr_overlap(dat$kde, type = "vi")
## # Тиббл: 3 × 4 ## уровни from to перекрываются #### 1 1 2 1 0,0432 ## 2 2 3 1 0,551 ## 3 3 4 1 0.612
Это также работает, если мы установим Conditional = TRUE :
hr_overlap(dat$kde, type = "vi", Conditional = TRUE)
## # Таблица: 9 × 4 ## уровни from to перекрываются #### 1 1 2 0,5 0 ## 2 1 2 0,95 0,0264 ## 3 1 2 0,99 0,0354 ## 4 2 3 0,5 0,259 ## 5 2 3 0,95 0,528 ## 6 2 3 0,99 0,547 ## 7 3 4 0,5 0,317 ## 8 3 4 0,95 0,592 ## 9 3 4 0,99 0,608
Иногда может быть полезно использовать осмысленные метки.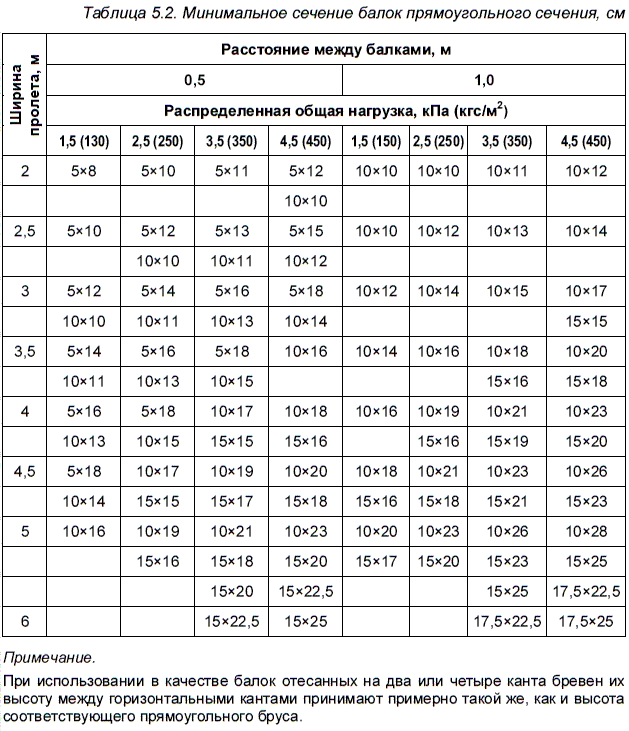 Мы можем сделать это с аргументом
Мы можем сделать это с аргументом labels .
hr_overlap(dat$kde, type = "vi", labels = dat$week)
## # tibble: 3 × 4 ## уровни from to перекрываются #### 1 2010-12-12 2010-12-191 0,0432 ## 2 19.12.2010 26.12.2010 1 0,551 ## 3 2010-12-26 2011-01-02 1 0.612
Существуют различные варианты аргумента который . Например, = "one_to_all" вычисляет перекрытие между первым и всеми остальными домашними диапазонами.
Наконец, мы можем вычислить перекрытие между всеми элементами внутри списка (для этого используйте , который = "все" ). Чтобы проиллюстрировать это, мы будем использовать puechcir из пакета adehabitatMA .
данные ("puechabonsp", package = "adehabitatMA")
dat <- puechabonsp$relocs %>% as.data.frame() %>%
make_track (X, Y, идентификатор = имя)
траст <- make_trast(dat, res = 50)
dat1 <- dat %>% гнездо (данные = -id) %>%
mutate(kde = map(data, ~ hr_kde(. , trast = trast, level = c(0.5, 0.9, 0.99))))
, trast = trast, level = c(0.5, 0.9, 0.99)))) Теперь мы можем вычислить совпадения между животными:
ov2 <- hr_overlap(dat1$ kde, type = "hr", labels = dat1$id, который = "all",
условно = ИСТИНА) %>%
фильтр (перекрытие > 0)
график <- as_tbl_graph(ov2) %>%
mutate (Популярность = степень_центральности (режим = 'в'))
ggraph(график, макет = 'напряжение') +
#geom_edge_fan(aes(col = перекрытие), show.legend = TRUE, стрелка = стрелка()) +
geom_edge_arc (aes (столбец = перекрытие), стрелка = стрелка (длина = единица (4, 'мм'), тип = «закрыто»),
start_cap = круг (3, 'мм'),
end_cap = круг (3, 'мм')) +
geom_node_point (размер = 4) +
geom_node_label (aes (метка = имя), отталкивание = ИСТИНА, альфа = 0,7) +
facet_edges(~ уровней, ncol = 2) +
тема_свет() +
scale_edge_color_gradient (низкий = "синий", высокий = "красный") Перекрытие между домашним диапазоном и простым объектом
Функция hr_overlap_feature позволяет вычислить процентное перекрытие (индекс \(HR\)) между домами. Чтобы проиллюстрировать эту особенность, мы снова воспользуемся данными из
Чтобы проиллюстрировать эту особенность, мы снова воспользуемся данными из лупе и рассчитаем пересечение с произвольным многоугольником.
poly <- bbox(lupe, buffer = -500, sf = TRUE) poly1 <- bbox(lupe, sf = TRUE) час <- hr_mcp(лупе) ggplot() + geom_sf (данные = hr_isopleths (hr)) + geom_sf(data = poly, fill = NA, col = "красный") + geom_sf(data = poly1, fill = NA, col = "синий")
hr_overlap_feature(hr, poly, direction = "hr_with_feature")
## # Набор символов: 1 × 3 ## от до перекрытия #### 1 0.95 1 0.828
hr_overlap_feature(hr, poly1, direction = "hr_with_feature")
## # Набор символов: 1 × 3 ## от до перекрытия #### 1 0.95 1 1.00
hr_overlap_feature(hr, poly, direction = "feature_with_hr")
## # Набор символов: 1 × 3 ## от до перекрытия #### 1 1 0,95 0,854
hr_overlap_feature(hr, poly1, direction = "feature_with_hr")
## # Набор символов: 1 × 3 ## от до перекрытия #### 1 1 0. 95 0.542
Та же работа с несколькими домашними уровнями:
hr <- hr_mcp(lupe, level = c(0.5, 0.9, 0.95)) hr_overlap_feature(hr, poly, direction = "hr_with_feature")
## # Набор символов: 3 × 3 ## от до перекрытия #### 1 0,5 1 0,828 ## 2 0,91 0,860 ## 3 0,95 1 0,990
Todo
ctmm реализует перекрытие для стационарного dist с ci: https://besjournals.onlinelibrary.wiley.com/doi/10.1111/2041-210X.13027
Сеанс
sessioninfo::session_info()
## ─ Информация о сеансе ────────────────────────────── ## значение параметра ## версия R версия 4.1.2 (2021-11-01) ## ОС Ubuntu 20.04.3 LTS ## система x86_64, linux-gnu ## пользовательский интерфейс X11 ## язык (EN) ## сопоставить C ## ctype en_US.UTF-8 ## tz Европа/Берлин ## Дата 2022-02-22 ## pandoc 2.14.0.3 @ /usr/lib/rstudio/bin/pandoc/ (через rmarkdown) ## ## ─ Пакеты ───────────────────────────────────────── ───────────────────── ## пакет * дата версии (UTC) источник lib ## amt * 0.1.7 22 февраля 2022 г. [1] местный ## assertthat 0.2.1 2019-03-21 [3] КРАН (Р 4.1.1) ## backports 1.4.1 13.12.2021 [3] CRAN (R 4.1.2) ## bslib 0.3.1 06.10.2021 [5] CRAN (R 4.1.1) ## мат 2.0.0 06.02.2020 [3] CRAN (R 4.1.1) ## класс 7.3-20 2022-01-13 [3] CRAN (R 4.1.2) ## classInt 0.4-3 07.04.2020 [3] CRAN (R 4.1.1) ## cli 3.1.1 20.01.2022 [3] CRAN (R 4.1.2) ## codetools 0.2-18 04.11.2020 [3] CRAN (R 4.1.2) ## colorspace 2.0-2 2021-06-24 [3] CRAN (R 4.1.1) ## мелок 1.4.2 29.10.2021[3] КРАН (Р 4.1.1) ## DBI 1.1.2 20.12.2021 [3] CRAN (R 4.1.2) ## дайджест 0.6.29 2021-12-01 [3] CRAN (R 4.1.2) ## dplyr * 1.0.7 2021-06-18 [3] CRAN (R 4.1.1) ## e1071 1.7-9 2021-09-16 [3] CRAN (R 4.1.1) ## многоточие 0.3.2 2021-04-29 [3] CRAN (R 4.1.1) ## оценить 0,14 2019-05-28 [3] CRAN (R 4.1.1) ## fansi 1.0.2 14.01.2022 [3] CRAN (R 4.1.2) ## farver 2.1.0 28 февраля 2021 г. [3] CRAN (R 4.1.1) ## fastmap 1.1.0 25.01.2021 [3] CRAN (R 4.1.1) ## дженерики 0.1.1 25.10.2021 [3] CRAN (R 4.1.1) ## ggforce 0.3.3 05.03.
2021 [3] CRAN (R 4.1.1) ## ggplot2 * 3.3.5 25.06.2021 [3] CRAN (R 4.1.1) ## ggraph * 2.0.5 23 февраля 2021 г. [3] CRAN (R 4.1.1) ## ггрепель 0.9.1 15 января 2021 г. [3] КРАН (R 4.1.1) ## клей 1.6.1 22.01.2022 [3] CRAN (R 4.1.2) ## graphlayouts 0.8.0 03.01.2022 [3] CRAN (R 4.1.2) ## gridExtra 2.3 2017-09-09 [3] CRAN (R 4.1.1) ## gtable 0.3.0 25.03.2019 [3] CRAN (R 4.1.1) ## выше 0,9 2021-04-16 [3] CRAN (R 4.1.1) ## htmltools 0.5.2 2021-08-25 [3] CRAN (R 4.1.1) ## igraph 1.2.11 2022-01-04 [3] CRAN (R 4.1.2) ## jquerylib 0.1.4 2021-04-26 [3] CRAN (R 4.1.1) ## jsonlite 1.7.3 17 января 2022 г. [3] CRAN (R 4.1.2) ## KernSmooth 2.23-20 2021-05-03 [3] CRAN (R 4.1.2) ##knitr 1.37 2021-12-16 [3] CRAN (R 4.1.2) ## маркировка 0.4.2 20.10.2020 [3] CRAN (R 4.1.1) ##решетка 0,20-45 2021-09-22 [6] КРАН (Р 4.1.1) ## жизненный цикл 1.0.1 2021-09-24 [3] CRAN (R 4.1.1) ## смазывать 1.8.0 07.10.2021 [3] CRAN (R 4.1.1) ## magrittr 2.0.1 2020-11-17 [3] CRAN (R 4.1.1) ## MASS 7.3-55 2022-01-13 [3] CRAN (R 4.1.
2) ## Matrix 1.4-0 2021-12-08 [6] CRAN (R 4.1.2) ## munsell 0.5.0 2018-06-12 [3] CRAN (R 4.1.1) ## столб 1.6.4 2021-10-18 [3] CRAN (R 4.1.1) ## pkgconfig 2.0.3 22 сентября 2019 г. [3] CRAN (R 4.1.1) ## поликлип 1.10-0 2019-03-14 [3] КРАН (Р 4.1.1) ## proxy 0.4-26 2021-06-07 [3] CRAN (R 4.1.1) ## муррр 0.3.4 17.04.2020 [3] CRAN (R 4.1.1) ## R6 2.5.1 2021-08-19 [3] CRAN (R 4.1.1) ## растр 3.5-15 2022-01-22 [3] CRAN (R 4.1.2) ## rbibutils 2.2.7 2021-12-07 [3] CRAN (R 4.1.2) ## Rcpp 1.0.8 2022-01-13 [3] CRAN (R 4.1.2) ## Rdpack 2.1.3 2021-12-08 [3] CRAN (R 4.1.2) ## rgdal 1.5-28 2021-12-15 [3] CRAN (R 4.1.2) ## ргеос 0,5-92021-12-15 [3] КРАН (R 4.1.2) ## rlang 0.4.12 2021-10-18 [3] CRAN (R 4.1.1) ## rmarkdown 2.11 2021-09-14 [3] CRAN (R 4.1.1) ## rstudioapi 0.13 12.11.2020 [3] CRAN (R 4.1.2) ## sass 0.4.0 12 мая 2021 г. [3] CRAN (R 4.1.2) ## весы 1.1.1 2020-05-11 [3] CRAN (R 4.1.1) ## sessioninfo 1.2.2 2021-12-06 [3] CRAN (R 4.1.2) ## sf 1.0-5 2021-12-17 [3] CRAN (R 4.1.2) ## sp 1.4-6 2021-11-14 [3] CRAN (R 4.
