
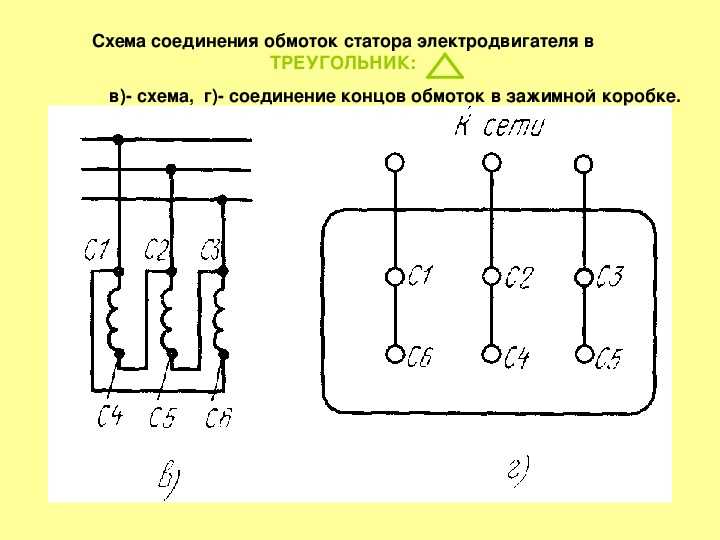
Двигатели. Серия 5АМХ
Серия 5АМХ
Асинхронные трехфазные электродвигатели с короткозамкнутым ротором. Применяются во всех отраслях народного хозяйства России и СНГ. Могут быть изготовлены для экспорта в страны с умеренным и тропическим климатом. Мощности привязаны к установочным размерам в соответствии с ГОСТ.
Встроенные датчикиВсе двигатели серии 5АМХ изготавливаются со встроенными датчиками температурной защиты.
Индивидуальное исполнениеДополнительные опции: климатическое исполнение, экспортное исполнение, нестандартный конец вала, пониженная вибрация, импортные подшипники, расположение коробки выводов и др. – в зависимости от потребностей заказчика.
Легкость и прочностьАлюминиевая станина и чугунные подшипниковые щиты обеспечивают снижение массы и усиление прочности конструкции.
Низкий нагревКоэффициент заполнения паза медью 0.84 гарантирует высокий КПД и уменьшение нагрева активных частей электродвигателя.
Эффективное охлаждениеРазвитое внешнее оребрение станины позволяет уменьшить рабочие температуры электродвигателя.
| Мощность, кВт | 5,5 – 30 |
| Напряжение, В | 220, 380, 660, 220/380, 380/660 экспорт – 240, 400, 415, 440 |
| Частота вращения, об/мин | 3000 – 750 |
| КПД, % | до 91,5 |
| Коэффициент мощности | до 0,91 |
| Степень защиты | IP54 (IP55 – опционально) |
| Исполнение по способу монтажа | IM1081, IM1082, IM2081, IM2082, IM3081, IM3082 |
| Способ охлаждения | IC411 |
| Режим работы | S1 — S6 |
| Условия запуска | прямой |
| Подшипники | качения |
| Класс нагревостойкости изоляции | F |
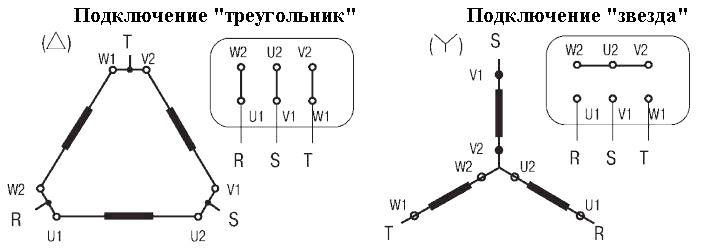
| Соединение фаз обмоток | звезда, треугольник, звезда/треугольник |
| Направление вращения | правое, левое (изменение вращения из состояния покоя) |
| Высота оси вращения, мм | 132, 160, 180 |
*Точные параметры указаны на страницах моделей двигателей.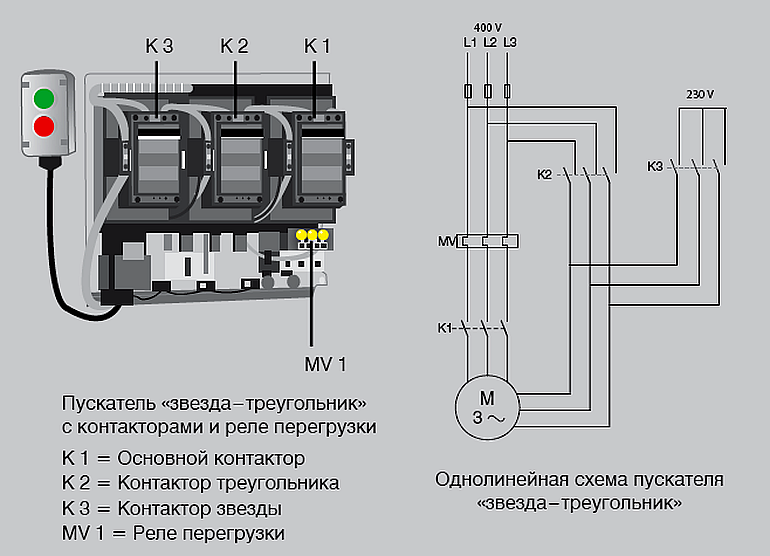
| Наименование | Мощность, кВт |
Синхронная частота вращения, об/мин |
Напряжение, В |
|---|---|---|---|
|
5АМХ132M2 |
11 |
3000 |
220/380; 380; 380/660 |
|
5АМХ160S2 |
15 |
3000 |
220/380; 380/660 |
|
5АМХ160M2 |
18,5 |
3000 |
220/380; 380/660 |
|
5АМХ180S2 |
22 |
3000 |
220/380; 380/660 |
|
5АМХ180M2 |
30 |
3000 |
220/380; 380/660 |
|
5АМХ132S4 |
7,5 |
1500 |
220/380; 380; 380/660 |
|
5АМХ132M4 |
11 |
1500 |
220/380; 380; 380/660 |
|
5АМХ160S4 |
15 |
1500 |
220/380; 380/660 |
|
5АМХ160M4 |
18,5 |
1500 |
220/380; 380/660 |
|
5АМХ180S4 |
22 |
1500 |
220/380; 380/660 |
|
5АМХ180M4 |
30 |
1500 |
220/380; 380/660 |
|
5АМХ132S6 |
5,5 |
1000 |
220/380; 380; 380/660 |
|
5АМХ132M6 |
7,5 |
1000 |
220/380; 380; 380/660 |
|
5АМХ160S6 |
11 |
1000 |
220/380; 380/660 |
|
5АМХ160M6 |
15 |
1000 |
220/380; 380/660 |
|
5АМХ180M6 |
18,5 |
1000 |
220/380; 380/660 |
|
5АМХ132S8 |
4 |
750 |
220/380; 380; 380/660 |
|
5АМХ132M8 |
5,5 |
750 |
220/380; 380; 380/660 |
|
5АМХ160S8 |
7,5 |
750 |
220/380; 380/660 |
|
5АМХ160M8 |
11 |
750 |
220/380; 380/660 |
|
5АМХ180M8 |
15 |
750 |
220/380; 380/660 |
Реле времени (для двигателей «звезда-треугольник») RT-SD EKF PROxima rt-sd
Личный кабинет
Ваш город Краснодар
по России звонок бесплатный
8-800-700-74-00
Ваша электробезопасность
Все товарыКабель и проводМодульное электрооборудованиеРозетки/ выключатели и комплектующиеСветильникиЛампыКабель-каналЛоток металлическийСчетчики электроэнергииТруба и металлорукавЭлектромонтажные изделияЭлектрооборудованиеЩиты0Корзина
0 р.
0
Отложенные
0
Сравнение
Главная Каталог МОДУЛЬНОЕ ЭЛЕКТРООБОРУДОВАНИЕ Реле контроля и управления на DIN-рейку Реле времени Реле времени (для двигателей «звезда-треугольник») RT-SD EKF PROxima rt-sd
Реле времени (для двигателей «звезда-треугольник») RT-SD EKF PROxima rt-sd
Характеристики
Описание товара
Отзывы (0)
Вопрос-ответ
Производитель:
EKF
Наличие на складе:
Нет
Артикул:
rt-sd
Вес:
0,082
Объем:
0,001
Ширина:
18,5
Длина:
65
Высота:
91,4
Срок службы, лет:
10
Номинальный ток:
8
Глубина:
49
С полупроводниковым выходом:
Нет
Временной диапазон:
0.
 075…600
075…600
Импульсное устройство:
Нет
Внешний склад:
26
Тип электрического подключения:
Винтовое соединение
Функция задержки на включение:
Нет
Подключение Звезда-Треугольник:
Да
Функция задержки на выключение:
Нет
Со штепсельн. гнездом/розеткой:
Нет
Перекидной контакт на включение:
Нет
Сменный блок дополнит. контактов:
Нет
«Реле времени RT-2C EKF PROxima является электронным коммутационным аппаратом с регулируемой установкой времени.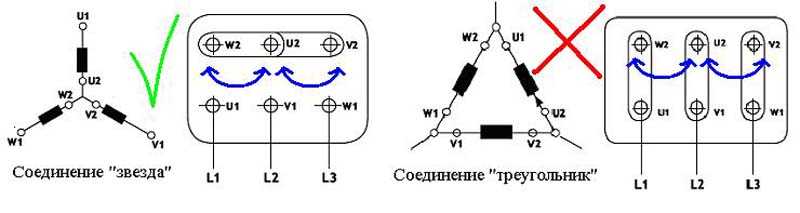 Реле предназначено для создания циклической работы схемы с задержкой на включение. Переключение диапазонов времени производится с помощью поворотных регуляторов, расположенных на лицевой поверхности реле.
Реле предназначено для создания циклической работы схемы с задержкой на включение. Переключение диапазонов времени производится с помощью поворотных регуляторов, расположенных на лицевой поверхности реле.
Реле применяется в системах промышленной и бытовой автоматики: в вентиляционных, отопительных, осветительных. Категория применения – АС-15 управление электромагнитами мощностью свыше 72 Вт.
Многофункциональное реле времени RT-10 EKF PROxima является электронным коммутационным аппаратом с регулируемыми режимами работы и регулируемой установкой времени. Реле предназначено для включения или отключения нагрузки по заданным временным величинам и режимам работы. Переключение диапазонов времени и режимов работы производится с помощью поворотных регуляторов расположенных на лицевой поверхности реле. Реле применяется в системах промышленной и бытовой автоматики: в вентиляционных, отопительных, о
г. Краснодар, ул Онежская, 60
Под заказ0
г.
 Краснодар, ул. Кр. Партизан, 194
Краснодар, ул. Кр. Партизан, 194Под заказ0
г. Краснодар, ул. Солнечная, 25
Под заказ0
г. Краснодар, ул. Дзержинского, 98/3
Под заказ0
г. Краснодар, ул. Уральская, 87
Под заказ0
г. Краснодар, ул. Российская, 252
Под заказ0
г. Краснодар Центральный склад
Под заказ0
г. Краснодар, ул. Западный обход, 34
Под заказ0
г. Краснодар, ул. К. Россинского, 7
Под заказ0
Внешний склад
В наличии26
Нет отзывов к товару
Оставить отзыв
Пожалуйста, авторизуйтесь чтобы иметь возможность оставить вопрос
.
 Форма ротора Ванкеля. Нунавут. Я давно собирался написать о другой очевидной теме в этой теме, о криволинейном треугольном роторе двигателя Ванкеля, но, в конце концов, меня заставили это сделать, когда я увидел две последние популярные книги по математике, Насколько круглая ваша окружность? (2008 г.) и Icons of Mathematics (2011 г.) повторяют ложь о том, что роторы Ванкеля являются треугольниками Рело. Они не.
Форма ротора Ванкеля. Нунавут. Я давно собирался написать о другой очевидной теме в этой теме, о криволинейном треугольном роторе двигателя Ванкеля, но, в конце концов, меня заставили это сделать, когда я увидел две последние популярные книги по математике, Насколько круглая ваша окружность? (2008 г.) и Icons of Mathematics (2011 г.) повторяют ложь о том, что роторы Ванкеля являются треугольниками Рело. Они не. В Википедии есть хорошая визуализация работы двигателей Ванкеля, которую я скопировал ниже. Они проходят те же четыре этапа, что и обычный четырехтактный двигатель внутреннего сгорания, в котором поршень отходит от камеры сгорания, всасывая смесь топлива и воздуха, толкается обратно к камере, сжимая смесь, воспламеняет смесь. выталкивая поршень обратно и прилагая усилие к приводному валу, а затем толкает обратно к камере, выталкивая выхлоп. Разница в том, что в двигателе Ванкеля эти четыре этапа происходят в четырех разных местах внутри камеры сгорания, поскольку газы внутри нее толкаются изогнутым треугольным поршнем, ротором двигателя.
Карданный вал в двигателе — фиксированная меньшая шестерня в центре анимации; в реальном двигателе эта шестерня сама вращалась бы, но это не показано. Треугольный ротор соединяется с карданным валом с помощью эксцентриковой планетарной шестерни и вращается вокруг карданного вала, как хула-хуп вокруг вращающейся танцовщицы. Шестерни имеют зубья и радиусы в соотношении 3: 2, в результате чего карданный вал вращается в три раза быстрее, чем ротор. При этом три угла ротора («верхние уплотнения») остаются в контакте с внешней стенкой двигателя, называемой его статором, так что газы в двигателе не просачиваются между разными фазами.
Форма статора определяется не изгибом самого ротора, а только траекторией движущихся уплотнений вершины. Эта траектория представляет собой кривую, называемую эпитрохоидой. Если вы когда-нибудь играли со спирографом, вы знаете, что такое эпитроихоид: это то, что вы получаете, фиксируя один круглый диск, позволяя другому круговому диску вращаться вокруг него, помещая точку где-то внутри вращающегося диска и прослеживая кривую, по которой он движется. следует. Вот еще одна анимация из Википедии:
следует. Вот еще одна анимация из Википедии:
Различные соотношения радиусов между внутренним и внешним диском дают разное количество лепестков на кривой, а различное расположение движущейся точки на внешнем диске (ближе или дальше от центра диска) дает кривые, которые ближе к круг или более пышные. Размещение движущейся точки на самом внешнем круге дает вам заостренные, а не изогнутые эпитрохоиды, а размещение ее еще дальше превращает внутренние выпуклости этих кривых в самопересекающиеся петли.
Траектории спирографа отличаются от траекторий вращения апексного уплотнения по крайней мере в трех отношениях: в двигателе Ванкеля центральный круг (карданный вал) вращается, а не остается неподвижным, внешний круг (планетарная шестерня) окружает центральный круг, а не вне его, а точка, движение которой прослеживается (вершинная печать), находится вне внешнего круга, а не внутри него. Тем не менее форма по-прежнему двухлопастная эпитрохоида; см. «теорему о двойном поколении» Бернуллиса, описанную Нэшем, 1 , почему одну и ту же кривую можно построить разными способами. По модулю масштаба всей системы имеется один свободный параметр, определяющий точную форму этой эпитрохоиды: отношение расстояний от центра ротора до апикальных уплотнений и до планетарной передачи. Если верхние уплотнения расположены слишком близко, планетарная передача врежется в статор; если они слишком далеко, статор будет близок к круглому, и давление от одной части цикла сгорания к другой изменится незначительно, что приведет к снижению эффективности двигателя. Выбор, сделанный в реальных двигателях, заключается не в том, чтобы разместить верхние уплотнения как можно ближе, а, по-видимому, в более тщательной оптимизации, которая учитывает форму и размер областей, образованных ротором и статором на разных стадиях цикла сгорания.
По модулю масштаба всей системы имеется один свободный параметр, определяющий точную форму этой эпитрохоиды: отношение расстояний от центра ротора до апикальных уплотнений и до планетарной передачи. Если верхние уплотнения расположены слишком близко, планетарная передача врежется в статор; если они слишком далеко, статор будет близок к круглому, и давление от одной части цикла сгорания к другой изменится незначительно, что приведет к снижению эффективности двигателя. Выбор, сделанный в реальных двигателях, заключается не в том, чтобы разместить верхние уплотнения как можно ближе, а, по-видимому, в более тщательной оптимизации, которая учитывает форму и размер областей, образованных ротором и статором на разных стадиях цикла сгорания.
Как только форма статора определена, можно переходить к ответу на вопрос, с которого мы начали: какова форма ротора? Основное конструктивное ограничение заключается в том, что он должен касаться или, по крайней мере, оставаться близко к внутренней выпуклости статора (на его «боковых уплотнениях»), чтобы предотвратить обратный поток выхлопных газов к впускному отверстию. Форму, которая достигает этого, можно понять с помощью мысленного эксперимента, в котором мы представляем ротор каким-то образом зафиксированным в пространстве, в то время как транспортное средство, содержащее его, вращается вокруг него, а не наоборот. При вращении транспортного средства его статор проходит части пространства, которые не могут быть заняты ротором. Части пространства, которые остаются нетронутыми вращающимся статором, доступны для использования ротором и должны использоваться им, если мы хотим, чтобы ротор оставался в контакте со статором на его боковых уплотнениях. Математически это описывается как «огибающая» положений вращающегося статора по отношению к неподвижному ротору. Эта оболочка представляет собой изогнутый треугольник, но не треугольник Рело. Его кривые более плоские, чем дуги треугольника Рело, но они также не являются дугами окружности. Как оболочка алгебраических кривых, они предположительно сами по себе алгебраичны, но более высокого порядка; тригонометрические формулы даны Шунгом и Пенноком.
Форму, которая достигает этого, можно понять с помощью мысленного эксперимента, в котором мы представляем ротор каким-то образом зафиксированным в пространстве, в то время как транспортное средство, содержащее его, вращается вокруг него, а не наоборот. При вращении транспортного средства его статор проходит части пространства, которые не могут быть заняты ротором. Части пространства, которые остаются нетронутыми вращающимся статором, доступны для использования ротором и должны использоваться им, если мы хотим, чтобы ротор оставался в контакте со статором на его боковых уплотнениях. Математически это описывается как «огибающая» положений вращающегося статора по отношению к неподвижному ротору. Эта оболочка представляет собой изогнутый треугольник, но не треугольник Рело. Его кривые более плоские, чем дуги треугольника Рело, но они также не являются дугами окружности. Как оболочка алгебраических кривых, они предположительно сами по себе алгебраичны, но более высокого порядка; тригонометрические формулы даны Шунгом и Пенноком. 2
2
На практике форма ротора отличается от идеальной формы оболочки эпитрохоида несколькими способами. Во-первых, как объясняет Дрогош, 3 для простоты изготовления часто аппроксимируется дугами окружности, а не точно повторяет форму конверта. Пока аппроксимация остается в пределах огибающей, ротор будет избегать столкновения со статором, а контакт бокового уплотнения не так важен вблизи углов треугольника, поэтому именно здесь аппроксимация наиболее заметна. Во-вторых, настоящие роторы Ванкеля часто имеют лопатки, выведенные из середины их сторон, чтобы сформировать мини-камеры сгорания, которые направляют и формируют дымовые газы внутри двигателя.
Подробнее обо всем этом см.:
Нэш, Дэвид Х. (1977), «Геометрия роторного двигателя», Mathematics Magazine 2: 87–89, doi: 10.1080/0025570X.1977.11976621, JSTOR: 2689731 ↩
Шунг, Дж.
-5 ↩ Б. и Пеннок, Г. Р. (1994), «Геометрия для машин трохоидального типа с сопряженными оболочками», Механизм и теория машин 29 (1): 25–42, doi: 10.1016/0094-114X(94)
Б. и Пеннок, Г. Р. (1994), «Геометрия для машин трохоидального типа с сопряженными оболочками», Механизм и теория машин 29 (1): 25–42, doi: 10.1016/0094-114X(94)Дрогош, П. (2010), «Геометрия роторного двигателя Ванкеля», Журнал KONES 17 (3): 69–74, http://yadda.icm.edu.pl/yadda/element/bwmeta1. element.baztech-article-BUJ5-0031-0018 ↩
(Обсудить на Mastodon)
Жизнь треугольника — логический конвейер NVIDIA
Опубликовано 16 марта 2015 г., 12:52
возможно, пришло время обновить основную графическую архитектуру под ним. Ферми был первым
Графический процессор NVIDIA, реализующий полностью масштабируемый графический движок, и его базовая архитектура могут быть
обнаружены как у Кеплера, так и у Максвелла. Следующая статья и особенно «сжатый
изображение конвейера знаний» ниже должно служить в качестве учебника, основанного на различных общедоступных
материалы, такие как технические документы или руководства GTC по архитектуре графического процессора. Эта статья
фокусируется на графической точке зрения на то, как работает GPU, хотя некоторые принципы, такие как
то, как выполняется программный код шейдера, одинаково для вычислений.
Эта статья
фокусируется на графической точке зрения на то, как работает GPU, хотя некоторые принципы, такие как
то, как выполняется программный код шейдера, одинаково для вычислений.
- Fermi Whitepaper
- Kepler Whitepaper
- Maxwell Whitepaper
- Fast Tessellated Rendering on Fermi GF100
- Programming Guidelines and GPU Architecture Reasons Behind Them
Pipeline Architecture Image
GPUs are super parallel work distributors
Why вся эта сложность? В графике нам приходится иметь дело с усилением данных, которое создает множество
переменных рабочих нагрузок. Каждый вызов отрисовки может генерировать разное количество треугольников. Количество
вершин после отсечения отличается от того, из чего изначально были сделаны наши треугольники. После отбраковки задней грани и глубины не всем треугольникам могут понадобиться пиксели на экране. Размер экрана треугольника может означать, что он требует миллионы пикселей или вообще не требует.
Как следствие, современные графические процессоры позволяют своим примитивам (треугольникам, линиям, точкам) следовать логическому конвейеру, а не физическому конвейеру. В старые времена, до появления унифицированной архитектуры G80 (вспомните аппаратное обеспечение DX9, ps3, xbox360), конвейер был представлен на чипе с различными этапами, и работа проходила через него один за другим. G80, по сути, повторно использовал некоторые единицы для вычислений как вершинных, так и фрагментных шейдеров, в зависимости от нагрузки, но по-прежнему имел последовательный процесс для примитивов/растеризации и так далее. С Fermi конвейер стал полностью параллельным, что означает, что чип реализует логический конвейер (шаги, через которые проходит треугольник) за счет повторного использования нескольких механизмов на чипе.
Допустим, у нас есть два треугольника A и B. Части их работы могут быть на разных этапах логического конвейера.
A уже был преобразован и нуждается в растрировании. Некоторые из его пикселей могут работать с пиксельным шейдером.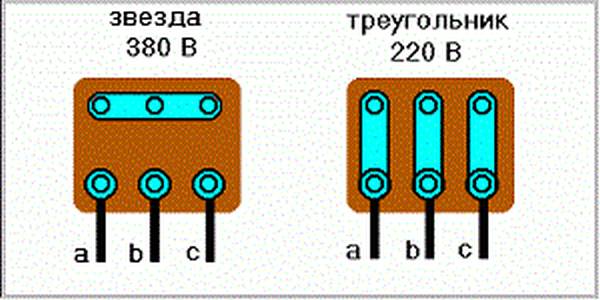 инструкции уже есть, в то время как другие отбрасываются буфером глубины (Z-cull), другие могут быть уже
записываются в фреймбуфер, а некоторые могут ждать. И рядом со всем этим, мы могли бы получить
вершин треугольника B. Таким образом, хотя каждый треугольник должен пройти логические шаги, многие из них могут быть
активно перерабатываются на разных этапах их жизни. Задача (получить треугольники drawcall на экране)
разделить на множество более мелких задач и даже подзадач, которые могут выполняться параллельно. Каждая задача назначена на
ресурсы, которые доступны, что не ограничивается задачами определенного типа (параллельное затенение вершин
к затенению пикселей).
инструкции уже есть, в то время как другие отбрасываются буфером глубины (Z-cull), другие могут быть уже
записываются в фреймбуфер, а некоторые могут ждать. И рядом со всем этим, мы могли бы получить
вершин треугольника B. Таким образом, хотя каждый треугольник должен пройти логические шаги, многие из них могут быть
активно перерабатываются на разных этапах их жизни. Задача (получить треугольники drawcall на экране)
разделить на множество более мелких задач и даже подзадач, которые могут выполняться параллельно. Каждая задача назначена на
ресурсы, которые доступны, что не ограничивается задачами определенного типа (параллельное затенение вершин
к затенению пикселей).
Представьте реку, которая расходится веером. Параллельные конвейерные потоки, независимые друг от друга, каждый на своей собственной временной шкале некоторые могут разветвляться больше, чем другие. Если бы мы кодировали блоки графического процессора цветом на основе треугольника или вызывали отрисовку, над которой он сейчас работает, это были бы многоцветные мерцающие огни 🙂
Архитектура графического процессора
Так как Fermi NVIDIA имеет аналогичную архитектуру. Существует Giga Thread Engine , который управляет всей текущей работой. Графический процессор разделен на несколько GPC (кластер обработки графики), каждый из которых имеет несколько SM (потоковый мультипроцессор) и один растровый процессор . В этом процессе существует множество взаимосвязей, в первую очередь Crossbar , который позволяет выполнять перенос работы между GPC или другими функциональными блоками, такими как подсистемы ROP (блок вывода рендеринга).
Существует Giga Thread Engine , который управляет всей текущей работой. Графический процессор разделен на несколько GPC (кластер обработки графики), каждый из которых имеет несколько SM (потоковый мультипроцессор) и один растровый процессор . В этом процессе существует множество взаимосвязей, в первую очередь Crossbar , который позволяет выполнять перенос работы между GPC или другими функциональными блоками, такими как подсистемы ROP (блок вывода рендеринга).
Работа, о которой думает программист (выполнение шейдерной программы), выполняется на SM. Он содержит много ядер , которые выполняют математические операции для потоков. Один поток может быть вершинным или пиксельным шейдером.
призыв например. Эти ядра и другие блоки управляются Warp Scheduler , которые управляют группой
из 32 потоков в качестве основы и передать инструкции для выполнения диспетчерским подразделениям . Логика кода обрабатывается планировщиком, а не внутри самого ядра, которое просто видит что-то вроде «суммировать регистр 4234 с регистром 4235 и сохранить в 4230» от диспетчера. Ядро само по себе довольно тупое по сравнению с процессором, где ядро довольно умное. GPU выводит интеллектуальность на более высокий уровень, он выполняет работу всего ансамбля (или нескольких, если хотите).
Логика кода обрабатывается планировщиком, а не внутри самого ядра, которое просто видит что-то вроде «суммировать регистр 4234 с регистром 4235 и сохранить в 4230» от диспетчера. Ядро само по себе довольно тупое по сравнению с процессором, где ядро довольно умное. GPU выводит интеллектуальность на более высокий уровень, он выполняет работу всего ансамбля (или нескольких, если хотите).
Сколько из этих блоков фактически находится на GPU (сколько SM на GPC, сколько GPC…) зависит от сама конфигурация чипа. Как вы можете видеть выше, GM204 имеет 4 GPC с каждым 4 SM, но Tegra X1, например, имеет 1 GPC и 2 SM, оба с дизайном Maxwell. Сам дизайн SM (количество ядер, блоков команд, планировщиков…) также менялся с течением времени от поколения к поколению (см. первое изображение) и помог сделать чипы настолько эффективными, что их можно масштабировать от высокопроизводительного настольного компьютера до ноутбука. мобильный.
Логический конвейер
Для простоты некоторые детали опущены. Мы предполагаем, что вызов отрисовки ссылается на некоторый index-
и вершинный буфер, который уже заполнен данными и живет в DRAM графического процессора и использует только вершины.
и пиксельный шейдер (GL: фрагментный шейдер).
Мы предполагаем, что вызов отрисовки ссылается на некоторый index-
и вершинный буфер, который уже заполнен данными и живет в DRAM графического процессора и использует только вершины.
и пиксельный шейдер (GL: фрагментный шейдер).
- Программа делает вызов отрисовки в графическом API (DX или GL). Это достигает драйвера в какой-то момент, что делает немного проверка, чтобы проверить, являются ли вещи «законными», и вставляет команду в кодировке, читаемой графическим процессором, внутри буфер . Здесь может возникнуть множество узких мест на стороне ЦП, поэтому важно, чтобы программисты хорошо использовали API и методы, которые используют мощь современных графических процессоров.
- Через некоторое время или явных вызовов «сброса» драйвер буферизировал достаточно работы в pushbuffer и отправляет ее на
обрабатывается GPU (с некоторым участием ОС). Хост-интерфейс графического процессора принимает команды, которые обрабатываются через внешний интерфейс .

- Мы начинаем распределение нашей работы в примитивном распределителе , обрабатывая индексы в индексном буфере и генерируя рабочие пакеты треугольников, которые мы отправляем в несколько GPC.
- Внутри GPC Poly Morph Engine одного из SM обеспечивает выборку данных вершин из индексов треугольников ( Vertex Fetch ).
- После получения данных внутри SM запланированы варпы из 32 потоков, которые будут работать над вершинами.
- Планировщик варпа SM выдает инструкции для всего варпа по порядку. Потоки выполняют каждую инструкцию в режиме блокировки и могут быть замаскированы индивидуально, если они не должны активно ее выполнять. Причин для такой маскировки может быть несколько. Например, когда текущая инструкция является частью ветви «if (true)», а данные, относящиеся к потоку, оценены как «false», или когда критерий завершения цикла был достигнут в одном потоке, но не в другом.
 Следовательно, наличие большого количества расхождений ветвей в шейдере может значительно увеличить время, затрачиваемое на все потоки в варпе. Нити не могут продвигаться по отдельности, только как варп! Деформации, однако, независимы друг от друга.
Следовательно, наличие большого количества расхождений ветвей в шейдере может значительно увеличить время, затрачиваемое на все потоки в варпе. Нити не могут продвигаться по отдельности, только как варп! Деформации, однако, независимы друг от друга. - Инструкция варпа может быть выполнена сразу или может занять несколько ходов отправки. Например, SM обычно имеет меньше единиц для загрузки/сохранения, чем выполнение основных математических операций.
- Поскольку некоторые инструкции выполняются дольше, чем другие, особенно загрузка памяти, планировщик деформации
может просто переключиться на другой варп, не ожидающий памяти. Это ключевая концепция того, как GPU
преодолевают задержку чтения памяти, они просто переключают группы активных потоков. Чтобы сделать это
переключение очень быстрое, все потоки, управляемые планировщиком, имеют свои собственные регистры в файле регистров.
Чем больше регистров требуется шейдерной программе, тем меньше места занимают потоки/деформации.
 Чем меньше деформации мы можем
переключаться между ними, тем менее полезная работа, которую мы можем выполнять, ожидая завершения инструкций (в первую очередь извлекается из памяти).
Чем меньше деформации мы можем
переключаться между ними, тем менее полезная работа, которую мы можем выполнять, ожидая завершения инструкций (в первую очередь извлекается из памяти). - После того, как варп выполнил все инструкции вершинного шейдера, его результаты обрабатываются Viewport Transform . Треугольник обрезается объемом пространства отсечения и готов к растеризации. Мы используем кэши L1 и L2 для всех этих межзадачных коммуникационных данных.
- Теперь становится интересно, наш треугольник вот-вот расколется и, возможно, покинет GPC, в котором он сейчас живет. Ограничивающая рамка треугольника используется для определения того, какие растровые механизмы должны работать с ним, поскольку каждый механизм покрывает несколько фрагментов экрана. Он отправляет треугольник одному или нескольким GPC через Перекладина рабочего распределения . Теперь мы фактически разделили наш треугольник на множество более мелких задач.

- Настройка атрибута в целевом SM гарантирует, что интерполянты (например, выходные данные, которые мы сгенерировали в вершинном шейдере) находятся в формате, удобном для пиксельного шейдера.
- Raster Engine GPC работает с полученным треугольником и генерирует информацию о пикселях для тех разделы, за которые он отвечает (также обрабатывает отбраковку задней поверхности и Z-отбор).
- Снова мы объединяем 32 пиксельных потока, или, лучше сказать, 8 умноженных на 2×2 пиксельных квадрата, что является наименьшим
unit, с которым мы всегда будем работать в пиксельных шейдерах. Этот квадрат 2×2 позволяет нам вычислять производные
для таких вещей, как фильтрация текстуры MIP-карты (большое изменение координат текстуры в квадроциклах вызывает
более высокий мип). Те потоки в квадрате 2×2, места выборки которых на самом деле не покрывают треугольник, маскируются (gl_HelperInvocation). Один из планировщиков деформации локального SM будет управлять задачей затенения пикселей.

- Та же самая игра с инструкциями планировщика деформации, которая была у нас на логическом этапе вершинного шейдера, теперь выполняется в потоках пиксельного шейдера. Пошаговая обработка особенно удобна, потому что мы можем получить доступ к значениям внутри пиксельного квадрата почти бесплатно, так как все потоки гарантированно чтобы их данные вычислялись до одной и той же точки инструкции (NV_shader_thread_group).
- Мы уже на месте? Наш пиксельный шейдер почти завершил расчет цветов для записи в rendertargets.
и у нас также есть значение глубины. На этом этапе мы должны принять во внимание исходный порядок треугольников в API.
прежде чем мы передадим эти данные в одну из подсистем ROP (блок вывода рендеринга), которая сама по себе имеет несколько
единицы РОП. Здесь выполняется проверка глубины, смешивание с фреймбуфером и так далее. Эти операции должны происходить
атомарно (одновременно устанавливается один цвет/глубина), чтобы гарантировать, что у нас нет цвета одного треугольника и глубины другого треугольника.
 значение, когда оба покрывают один и тот же пиксель.
NVIDIA обычно применяет сжатие памяти, чтобы уменьшить требования к пропускной способности памяти, что увеличивает «эффективную» пропускную способность (см.80 ПДФ).
значение, когда оба покрывают один и тот же пиксель.
NVIDIA обычно применяет сжатие памяти, чтобы уменьшить требования к пропускной способности памяти, что увеличивает «эффективную» пропускную способность (см.80 ПДФ).
Фу! мы закончили, мы записали некоторый пиксель в rendertarget. Я надеюсь, что эта информация была полезной чтобы понять часть работы/потока данных внутри графического процессора. Это также может помочь понять другой побочный эффект почему синхронизация с процессором действительно вредна. Приходится ждать, пока все закончится, и нет отправляется новая работа (все блоки становятся бездействующими), это означает, что при отправке новой работы требуется некоторое время, пока все снова полностью загружено, особенно на больших графических процессорах.
На изображении ниже вы можете увидеть, как мы визуализировали модель CAD и раскрасили ее с помощью различных SM или деформации.
идентификаторы, которые участвовали в изображении (NV_shader_thread_group). Результат не будет кадрово-когерентным,
поскольку распределение работы будет варьироваться от кадра к кадру.